Solving Pagination: How MrScraper Deliver The Most Complete, Precise, and Optimized Listing Results

Executive Summary
Extracting structured data from the web is no longer about parsing static HTML; it’s about handling dynamic content loading. From infinite scrolls to complex content updates, modern listing pages treat data delivery as a moving target, making reliable extraction increasingly difficult. MrScraper’s Listing Agent addresses this complexity not with fixed rules, but with adaptive navigation. By treating every listing as an unknown environment, the agent observes, classifies, and reacts to the page’s interaction model in real time. This article explores the engineering decisions and architectural principles behind this approach, detailing how we moved from brittle selectors to a generalized pipeline capable of handling any listing structure.
How Websites Actually Behave
Good scraping tools don't just extract data; they ensure the complete and precise discovery of all available data. To achieve this, they must remain reliable, easy to operate, and flexible enough to handle diverse website structures, from simple static pages to complex, dynamic, or irregularly paginated layouts. Whether for price intelligence, competitive analysis, or large-scale research, the value of a dataset is determined by its completeness. However, achieving 100% coverage is an architectural challenge because websites use widely different pagination patterns and page-loading behaviors.
Standardizing the web is deceptively difficult. When developing the Listing Agent, we encountered massive variance in how modern websites structure their data fetching and navigation. A naive scraper expects a static page, but the modern web has dynamic environment of Single Page Applications (SPAs), content rendered progressively, and obfuscated navigation. Many sites use lazy rendering, where only an initial skeleton of content loads and the rest appears gradually, triggered by scrolling, clicking, or other interactions. To handle this, the Listing Agent mimics human behavior with gradual, iterative scrolling, allowing the site’s JavaScript to fetch additional items in real time. This ensures every listing is revealed, improves reliability of content capture, and reduces anti-bot detection by simulating natural scroll patterns with variable speed and pauses. Some pages combine both approaches, serving a few items server-side while hiding dozens more behind lazy loading, making behavior detection crucial for complete data extraction. Our research found that listing navigation generally falls into three distinct archetypes:
1. Traditional Pagination : The classic "Next" button or page numbers (1,2,3...).
2. Infinite Scroll : Content appends automatically as the viewport descends.
3. Load More : A button explicitly requests the next batch of data to append to the current DOM.
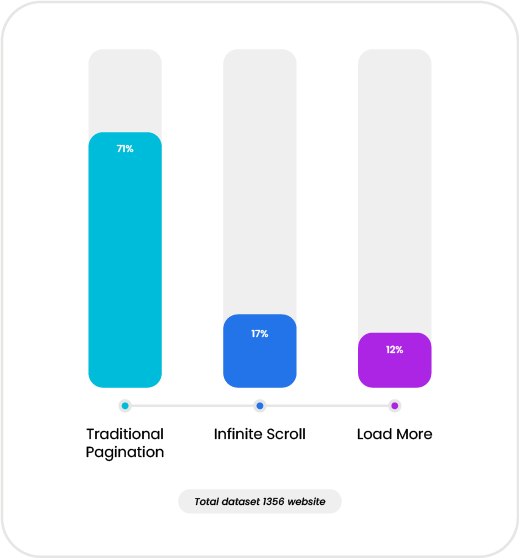
Our internal dataset of over 1356 analyzed domains shows that the web splits into 3 dominant pagination patterns, Next-Button Pagination, Infinite Scroll, and Load-More Button. This dataset reveals a fractured landscape roughly 71% of sites still rely on Traditional Pagination, a pattern predominantly found in older architectures or high-SEO sites where distinct page URLs are preferred. Meanwhile, 17% have shifted to Infinite Scroll, now dominant in social platforms and modern feed-style commerce to maximize engagement. The remaining 12% utilize Load More buttons, where user intent is required to append data to the current view. This diversity implies that a rigid, rule-based scraper is destined to fail; an effective agent must be fluid and adaptive.
How We Build Listing Agent That Discover Variety of Website Structure
To solve the discovery problem while keeping the tool accessible to beginners, we needed a way to automatically detect pagination patterns without requiring users to write complex rules. This led us to develop a system centered on Pagination Type Detection and Lazy Rendering Handling, enabling the crawler to infer navigation behavior directly from a page’s structure.
One of our core engineering insights was that scanning the entire DOM for navigation cues is computationally heavy and highly prone to noise. Raw HTML contains thousands of irrelevant tokens such as analytics scripts, heavy SVG paths, and base64 images. Sending this unfiltered content to a classification model increases latency and decreases accuracy.
To address this, we engineered an in-house HTML Cleaner, specifically designed through our research to truncate and preserve only the structural content that matters. The cleaner not only removes unnecessary elements but also applies a truncation threshold, so if the cleaned HTML exceeds a pre-defined character limit, the remaining content is truncated. This approach preserves performance and keeps classification cost predictable. Our cleaner operates through two distinct phases before any classification occurs:
1. Noise Elimination, The system strips non-structural elements. Tags like <script>, <style>, , and <iframe> are removed, along with semantic regions like or that rarely contain pagination. We also trim attributes, removing tracking metadata and shortening long URIs.
2. Structural Collapse, Listing pages are defined by repetition—hundreds of product cards or table rows. We don't need to read every item to know a list exists. Our cleaner generates an "Element Signature" for each node (tag + class + attributes). When it detects long runs of identical signatures (e.g., 50 repeated div.product-card), it collapses them into a single placeholder. This preserves the structure of the list while reducing HTML size by up to 90%.
Once we obtained a clean HTML structure, one challenge remained: truncation could unintentionally remove critical pagination elements. Based on our research across 1,356 websites, we found that 98% of “Next” buttons and other pagination controls are located at the bottom of the HTML document. To maintain optimal speed, accuracy, and completeness, we therefore apply a length threshold that preserves the bottom portion of the HTML, ensuring these navigation elements are retained.
This large-scale analysis revealed a consistent pattern: pagination and navigation logic almost always reside in the lower segments of the document. Building on this insight, we adopt a bottom-focused extraction strategy. Instead of feeding the entire cleaned HTML to the model, we route the document through a specialized funnel that preserves only the essential structural components—specifically isolating the segment where navigation controls are physically rendered. This guarantees reliable detection of pagination while keeping processing efficient and robust.

In this pipeline, the raw HTML is ingested, stripped of noise, structurally collapsed to remove redundancy, and finally truncated to the bottom context before entering the LLM as Classification Engine. This approach ensures high-precision detection with minimal token usage, enabling significantly faster classification.
Detecting the navigation type is only half the battle; the agent must also respect the timing of the web. Many scrapers fail because they try to extract data before the browser has finished rendering content. To solve this, we implemented Iterative Scrolling, where the agent scrolls down the page periodically, in human-like increments, instead of jumping straight to the bottom. After each scroll, it monitors network activity and DOM changes, if the page loads new items or the DOM height increases, the agent recognizes a "Lazy Load" event and waits until the content stabilizes. This approach not only mimics human browsing behavior but also allows users to control scrape depth with simple parameters like max page, leaving the complex navigation logic entirely to the agent.
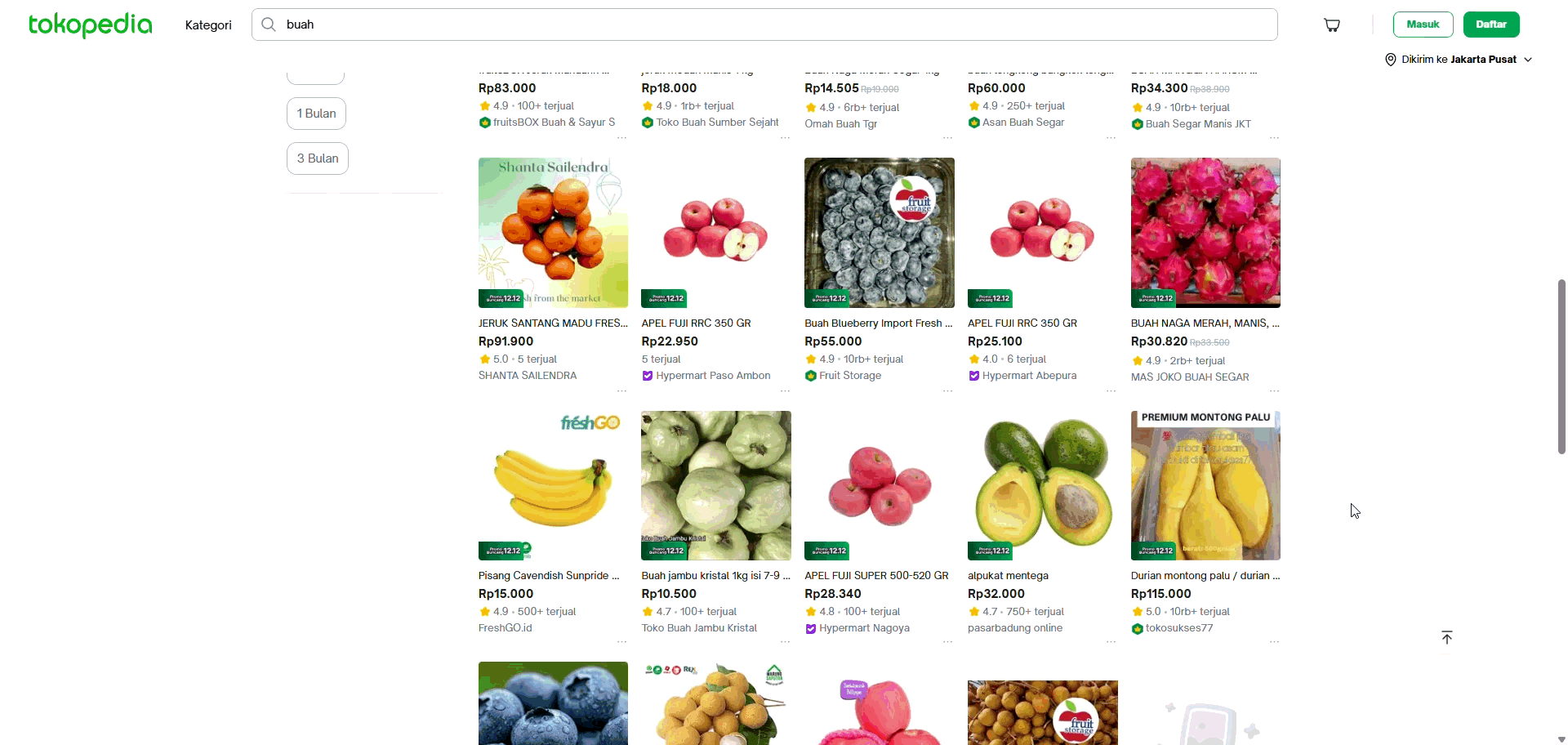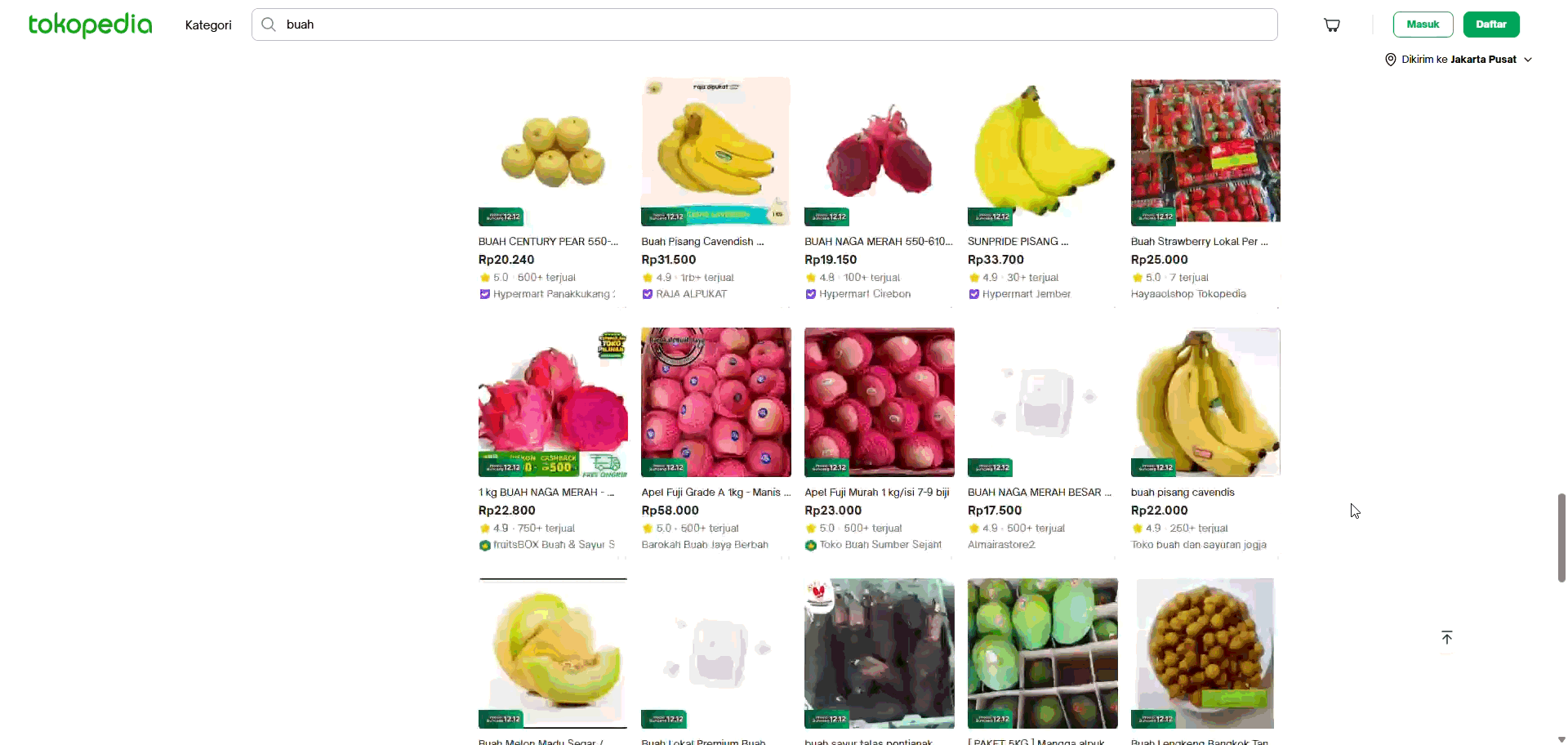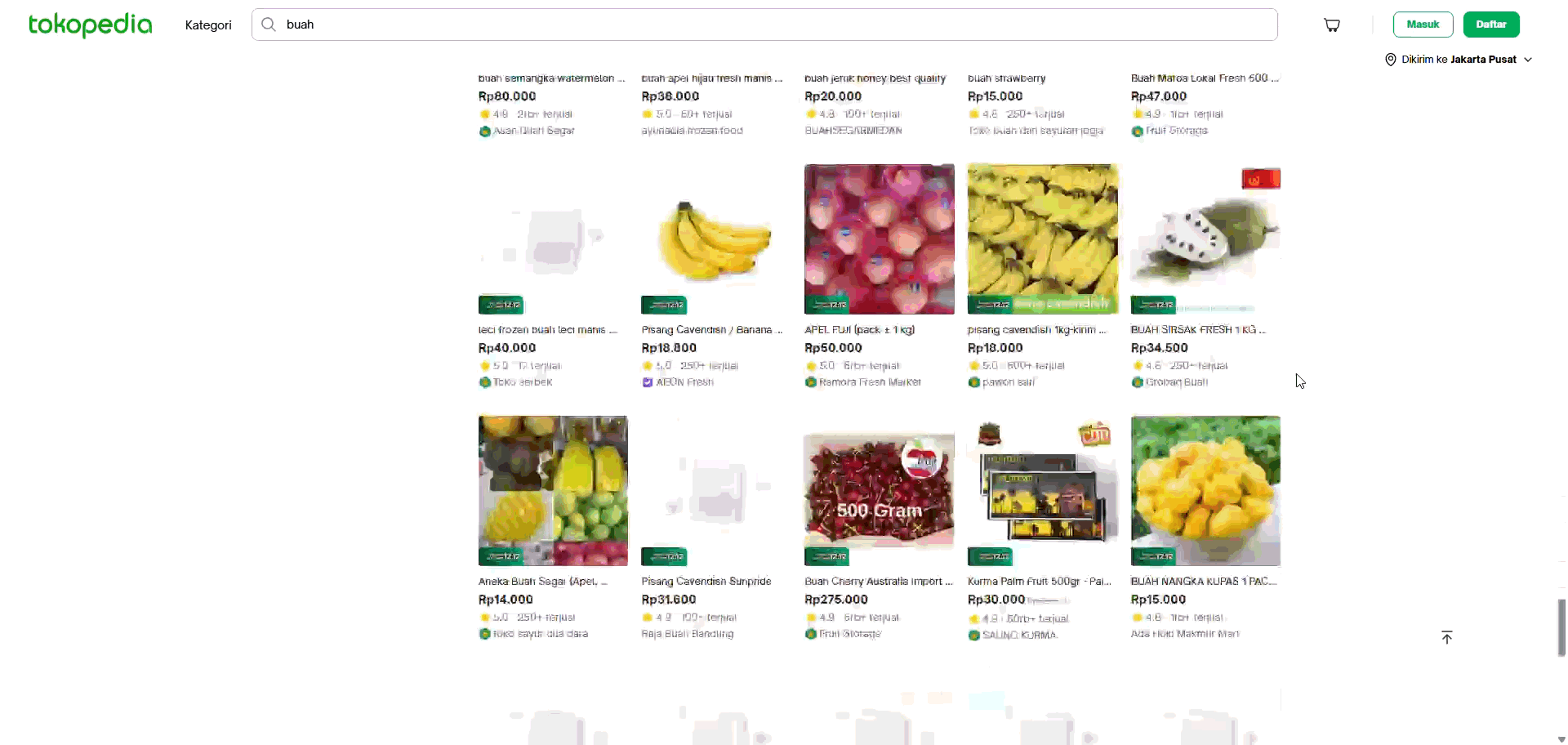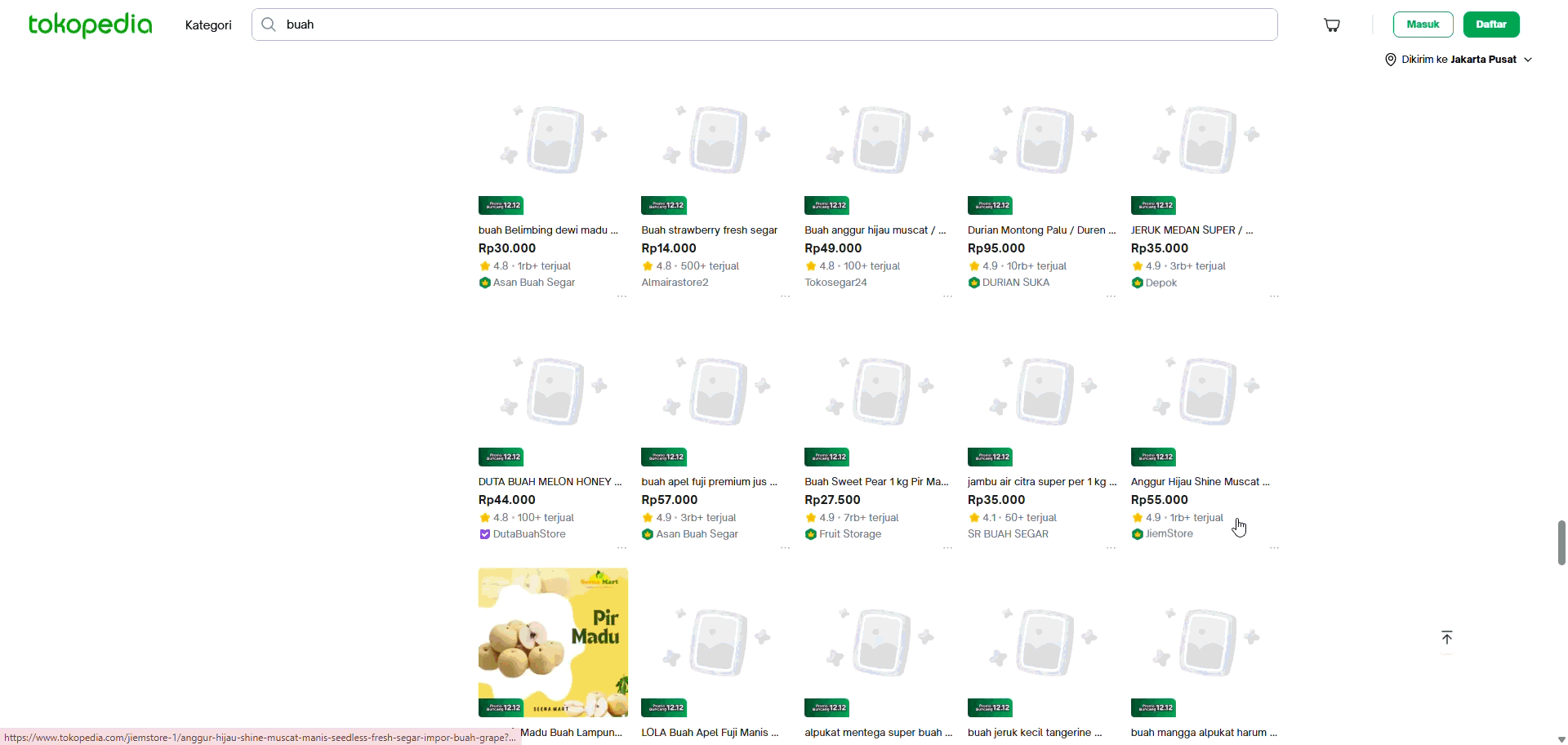
Once the agent successfully identifies the pagination type, whether Next Button, Infinite Scroll, or Load More, it transitions from understanding the structure to acting on it. Because the system already detects lazy-loading triggers through iterative scrolling, it can fully automate the entire navigation sequence, scrolling in controlled increments to surface hidden items, waiting for load contents, or clicking through paginated URLs as needed. Combined, these capabilities transform the agent from a passive classifier into an autonomous navigator, capable of reliably exploring the full breadth of diverse website structures without requiring the user to script a single rule.
When Patterns Lie
The biggest hurdle in automated scraping is "visual ambiguity," where elements look like navigation but serve a different purpose. Through our testing, we identified three critical edge cases that required specific engineering solutions to ensure high accuracy.
Many product cards include internal image sliders with small “Next” arrows, a pattern we refer to as the Carousel Trap. These arrows frequently generate false positives for automated navigation systems. From a CSS-selector perspective, the elements look indistinguishable from global pagination controls; however, clicking them only cycles through product photos rather than advancing to the next page of results. To avoid this misclassification, our approach evaluates the structural context of the element. When a “Next” button is found inside a repeated list item, such as within a product card, we treat it as a local UI component instead of a global navigation mechanism.
In addition, some platforms use what we identify as Fake Infinite Scroll, a UX pattern where the interface behaves like infinite scroll only for the first portion of content. After a certain depth, automatic loading stops to conserve backend resources, forcing users to click a hidden or newly revealed control to proceed. A naïve infinite-scroll crawler would endlessly wait at the bottom of the page for data that never arrives. To prevent this deadlock, our agent employs a timeout-driven state assessment. When no new content appears after sustained scrolling, it triggers a full DOM re-scan to detect any fallback mechanisms, such as a “Load More” button or a suddenly exposed pagination link.
We also encounter a more complex scenario, which we classify as Hybrid Navigation, commonly found in architectures similar to those of large media platforms. These systems may initially load content through infinite scroll and then transition to a button-based model once certain thresholds are reached. Rather than treating navigation as a static, one-time classification at page load, our agent maintains a fluid, ongoing evaluation. If scroll listeners stop returning new items, the system immediately shifts its strategy by inspecting the updated footer region for elements that become visible only after the infinite-scroll phase ends, enabling seamless continuation even as the navigation paradigm shifts mid-session.
The Listing Agent demonstrates that robust listing extraction is not achieved by brittle selectors or single-pattern assumptions but by treating each page as an active environment to be observed, probed, and classified. By combining controlled interaction such as human-like scrolling and clicks, structural normalization of the DOM, behavioral validation, and a domain-level cache, the agent delivers reliable, repeatable discovery across diverse site architectures while keeping operational cost predictable. These design choices shift the problem from fragile per-site engineering to a generalized, testable pipeline, which already yields strong results in the wild and provides a solid foundation for the targeted improvements we describe next.
Why Our Approach is Superior
We designed this architecture with careful research and engineering to create a truly general-purpose scraping agent. By studying common patterns across thousands of websites, and analyzing many representative ai scraping products and comparing their structures against common industry approaches we focused on building a system that is reliable, efficient, and adaptable.
- Robust Pagination Detection Our agent prioritizes detecting pagination and navigation patterns, making it highly reliable across a wide range of websites—including Single Page Applications (SPAs) and dynamically loaded content. Unlike approaches that depend on simply following URLs to reach the next page, our agent can handle infinite scrolls, "Load More" buttons, and other modern web structures, ensuring that no data is overlooked.
- Optimized Time and Cost Efficiency Our agent minimizes LLM usage by relying primarily on lightweight structural inference to determine the next steps, reserving heavier computation for only the most complex scenarios. This design significantly reduces processing time and cost while maintaining accuracy. By contrast, approaches that invoke Vision LLMs for every interaction may incur higher latency and cost due to overuse of computational resources.
What’s Next: Future Enhancements
Our next focus is pushing navigation-type detection and environment-behavior classification even further.
1. Vision-Language Models
We are currently refining the Listing Agent to handle the next generation of web complexity. As HTML structure becomes more obfuscated with Shadow DOMs and randomized class names, relying solely on code structure has its limits. We are experimenting with Vision-Language Models (VLMs) to allow the agent to "see" the page render, identifying navigation buttons based on visual placement and iconography rather than just code. Additionally, we are expanding our capabilities to detect and gracefully handle advanced bot protections and complex captchas that attempt to interrupt the navigation flow, ensuring longer-running scrapes remain uninterrupted.
2. Deeper Environment–Behavior Classification
We are building a more intelligent behavior-classification system that can understand how a page responds to user actions. The goal is to precisely categorize interaction behaviors, detect transitions between different interaction modes, and interpret dynamic rendering patterns—resulting in a faster, more accurate understanding of any website’s environment.
Table of Contents
Interested in our research?
Learn how MrScraper's AI-powered web scraping can help your business extract data at scale.
Book a CallGet started now!
Step up your web scraping
More Research

How Mrscraper Uses DAG Pipeline to Build the Most Reliable Web Scraper Agent
Mrscraper Agent is an AI-powered web scraping system designed as a directed acyclic graph (DAG) pipe...