
How to Extract and Download News Articles Online with Ease
GuideLearn how to easily extract and download news articles online with MrScraper. Follow this simple step-by-step guide to gather news data for offline access, research, and trend tracking. Perfect for researchers, content creators, and marketers.
Keeping up with the latest news often means visiting multiple websites and sorting through lots of information. But what if there was an easier way to gather and save all the news you need in one place? In this guide, we’ll show you exactly how to extract and download news articles online in a few simple steps. Whether you need articles for research, trend analysis, or personal archives, some tools and methods make it easy to organize and store relevant news.
Why Download News Articles?
Downloading articles from your favorite news sites can help you:
- Access Articles Offline: Perfect for reading anytime, even without an internet connection.
- Compile Articles for Research: Researchers and analysts often need large data sets for thorough analysis.
- Stay on Top of Trends: Marketers and content creators can track trending topics for better audience insights.
Now, let’s dive into how to extract and download news articles using MrScraper.
Step-by-Step Guide to Extract and Download News Articles Using MrScraper
Follow these easy steps to start downloading articles with MrScraper:
1. Sign Up for MrScraper
If you’re new to MrScraper, start by creating an account on the MrScraper website. The platform is intuitive and straightforward, ideal for extracting data without any coding requirements.
2. Visit the News Website
Next, head to the news website you want to scrape. For example, if you’re interested in technology news, navigate to that section of the site. Copy the URL of the section or page you’d like to scrape, as you’ll need it in the next step.
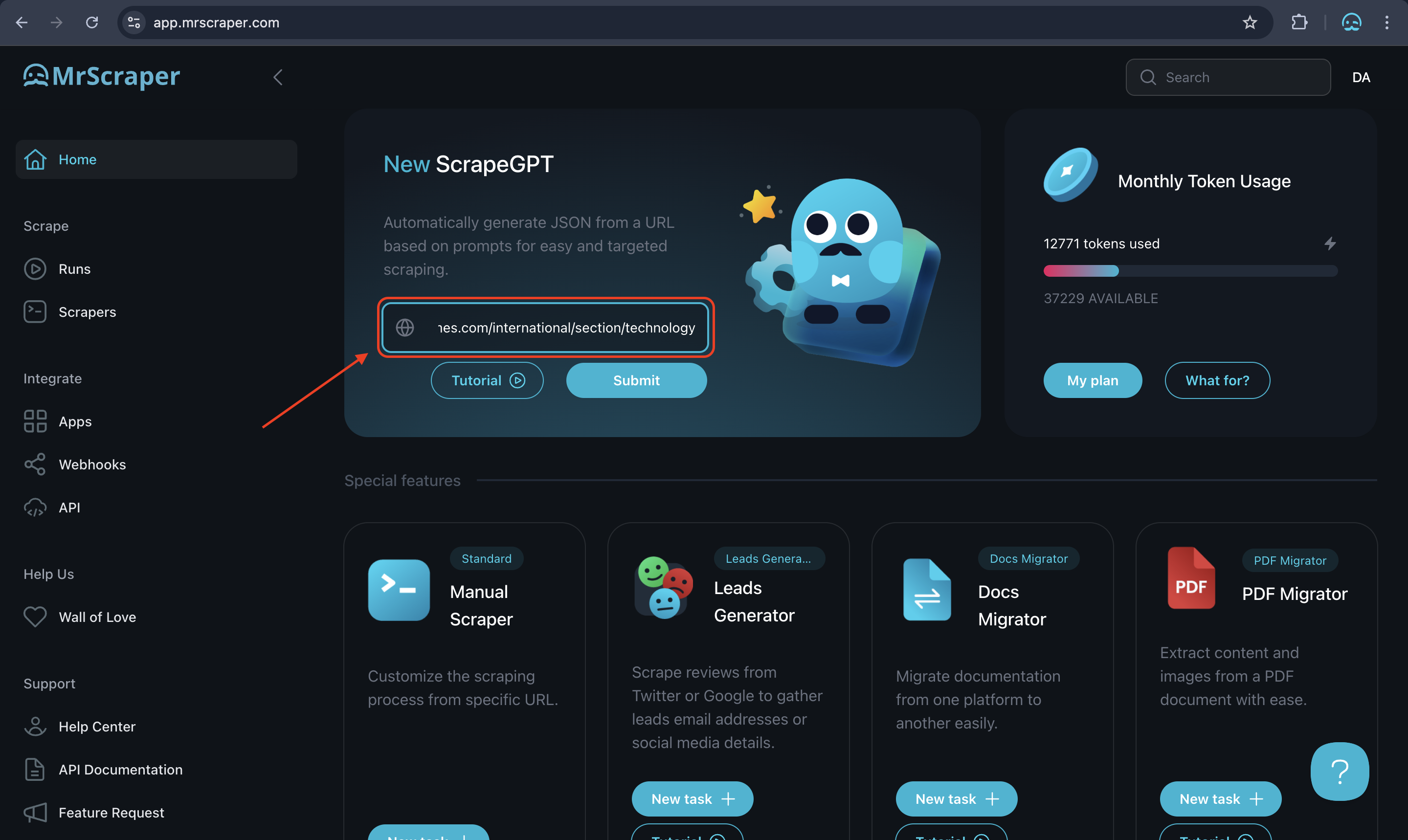
3. Configure MrScraper for the News Website
Once you’re logged into MrScraper, go to the home page and create a new scraping project. In the project setup, paste the URL of the news website into the ScrapeGPT feature. This tells MrScraper where to gather data from. Make sure you’re using a URL that targets the specific section you’re interested in, , such as “https://www.nytimes.com/international/section/technology.”
4. Allow ScrapeGPT to Load and Enter the Prompt
After loading the news site’s page within MrScraper, type the prompt “Get All the Data” to instruct ScrapeGPT to extract the available listings or articles. This will initiate the scraping process, where MrScraper begins gathering information such as headlines, publication dates, and article content.
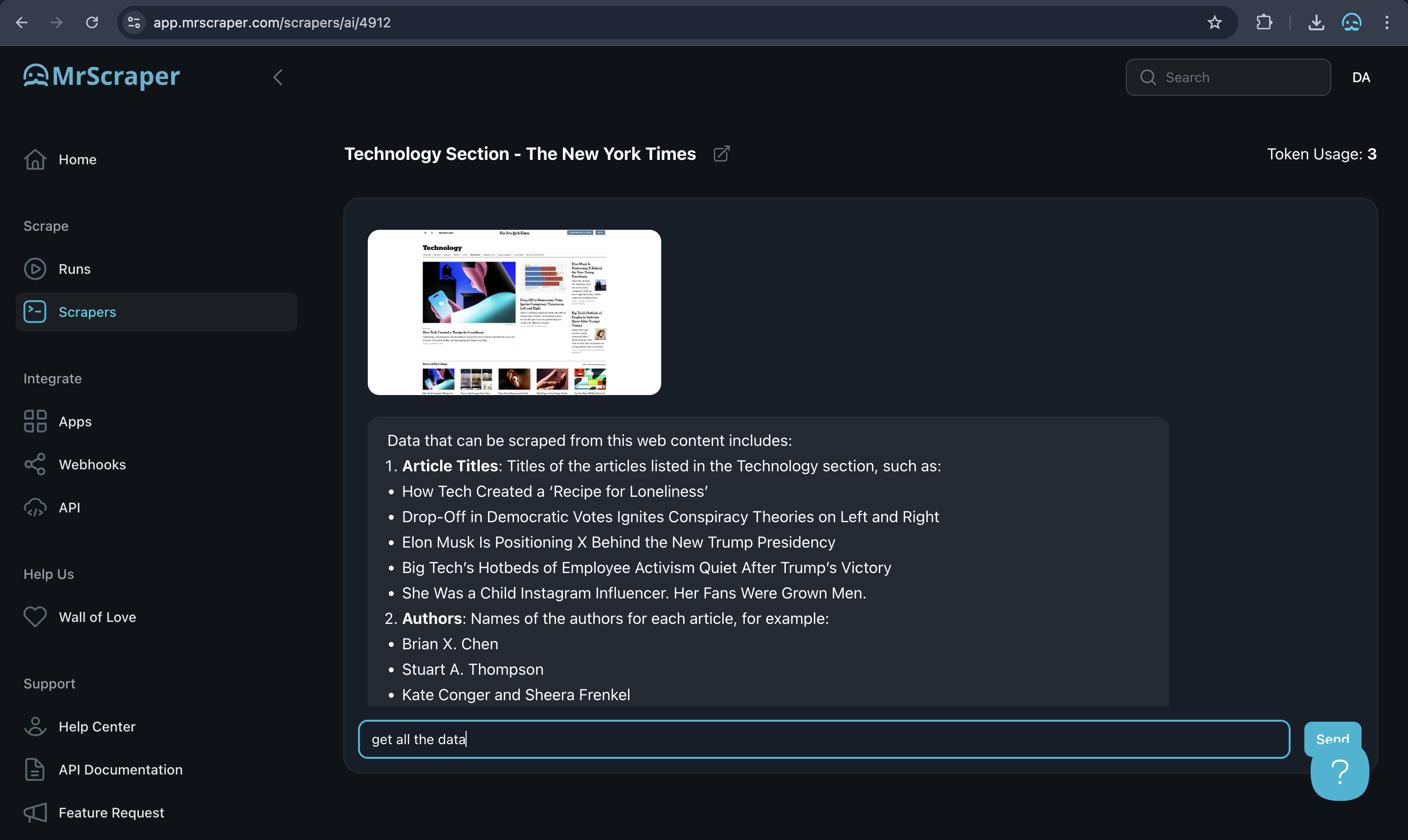
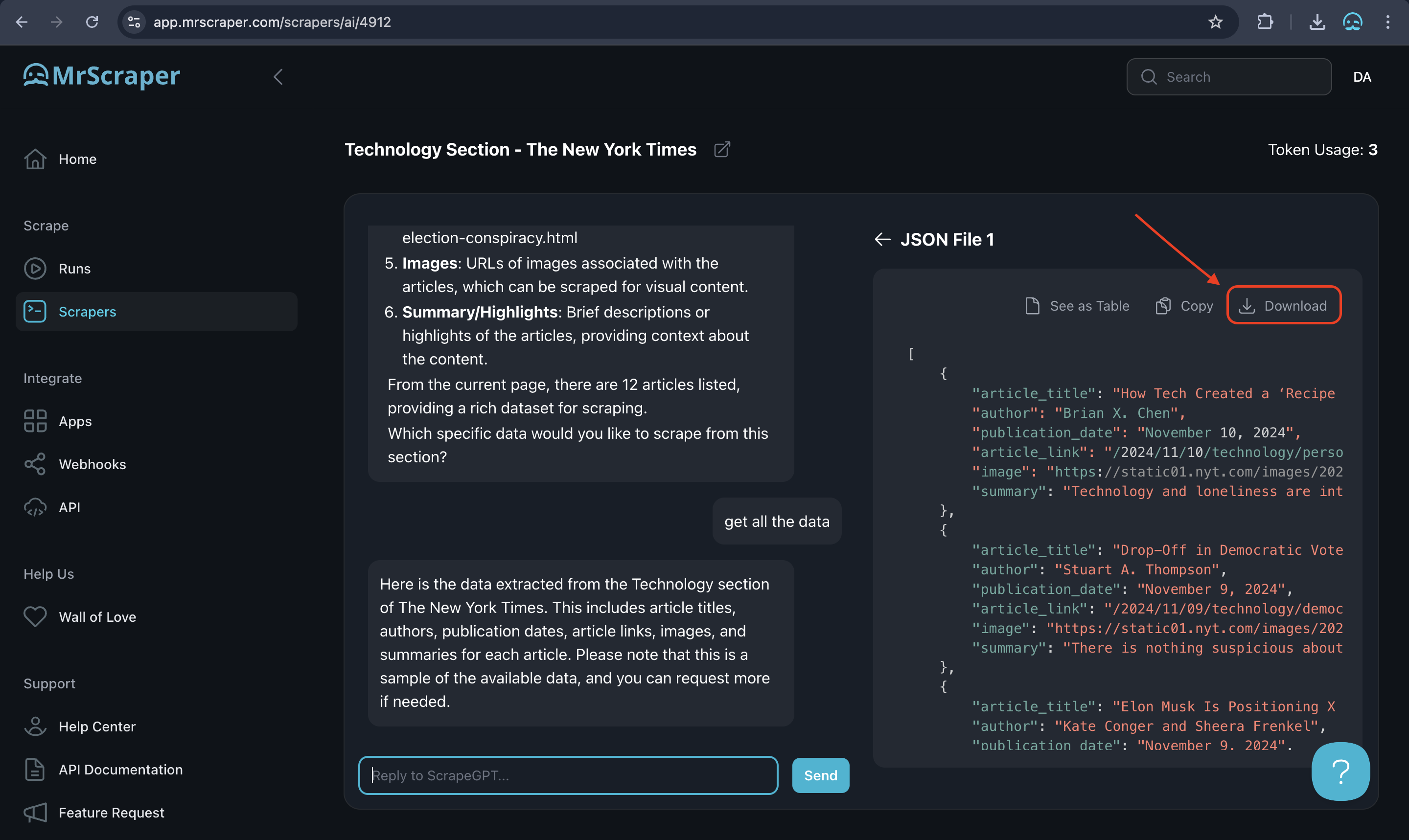
5. Review and Download Your Data
Once ScrapeGPT completes the data extraction, you can review the results directly in MrScraper to ensure you have the information you need. When satisfied, download the data in either JSON or CSV format. These formats make it easy to analyze, organize, or integrate the data into your workflow.
Quick Tips for Optimizing Your Scraping with MrScraper
- Use Specific URLs: Target URLs from specific sections like “technology news” or “business headlines” for more accurate results.
- Save Your Configurations: MrScraper allows you to save your setup for future use, making it easy to repeat the process.
Start Downloading News Articles Today
Whether you're a researcher, a marketer, or just someone who loves staying informed, downloading news articles online is easier than ever with the right tools. With MrScraper, you can access and save all the latest news in a few clicks. Get started today, and see how MrScraper can simplify your news-gathering process!
Find more insights here

How to Scrape Websites Without Getting Blocked: A Complete Guide
A complete guide to scraping websites without getting blocked — proxy rotation, browser fingerprinti...

Web Scraping API Guide: How They Work and When to Use One
A complete guide to web scraping APIs — how they work, the different types, when to use one vs. buil...

How to Scrape Multiple Pages With a Web Scraping API (Step-by-Step Guide)
Learn how to scrape multiple pages with a web scraping API — handling URL, offset, cursor, and JavaS...
