
How MrScraper Adopts Acyclic Task-Specific Agent To Build The Most Reliable Web Scraper Agent
EngineeringMrscraper Agent is an AI-powered scraping system built on a deterministic DAG pipeline, turning complex data extraction into simple natural-language prompts. Instead of fragile scripts, users describe the data they need, and specialized agents execute their DAG stages, mapping domains, detecting listings, and extracting structured information with reliable, predictable performance at scale.
Data has become the fundamental resource driving modern business decisions, often described as "the new oil" of the digital economy. However, a critical gap exists between recognizing data's value and actually extracting it. Traditional web scraping presents significant engineering challenges: developers typically spend days or weeks crafting custom scripts for each target website, managing DOM variations, handling pagination logic, and maintaining brittle selectors that break with minor UI changes.
The proliferation of diverse website architectures compounds this problem. E-commerce platforms alone exhibit thousands of structural variations—from server-side rendered marketplaces to React-based SPAs with infinite scroll, from traditional pagination to load-more patterns. Each requires a fundamentally different extraction approach.
In an era where AI has democratized complex tasks through natural language interfaces, data extraction remains frustratingly technical. Business analysts who can articulate exactly what data they need still require engineering resources to build and maintain scrapers. This bottleneck prevents organizations from rapidly responding to market intelligence opportunities.
Mrscraper Agent addresses this fundamental accessibility problem. It's an agentic scraping system that enables end-to-end data extraction through natural language prompting—from domain-level exploration to detailed product information extraction. Mrscraper Agent's consists of three specialized AI agents, each optimized for a distinct phase of the scraping pipeline:
- Map Agent: Domain crawling and link discovery
- Listing Agent (Category/Browse/Collection): All listing data and their corresponding URLs from the page.
- General Agent (Data Extraction): Extracts structured data from any targeted page (listing pages or product/detail pages) based on user-requested fields.
This architecture allows users to execute comprehensive scraping workflows—traditionally requiring hundreds of lines of custom code—using simple prompts like "extract all listing from example.com."
How Mrscraper Agent Works
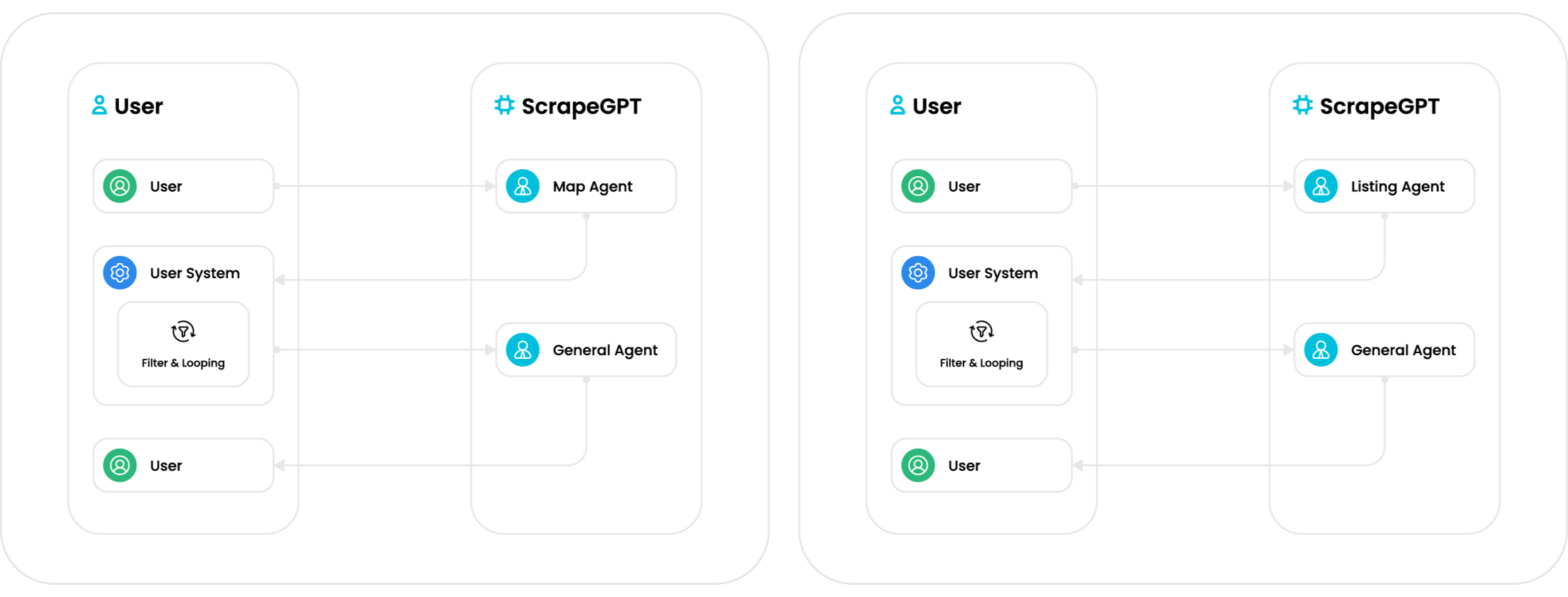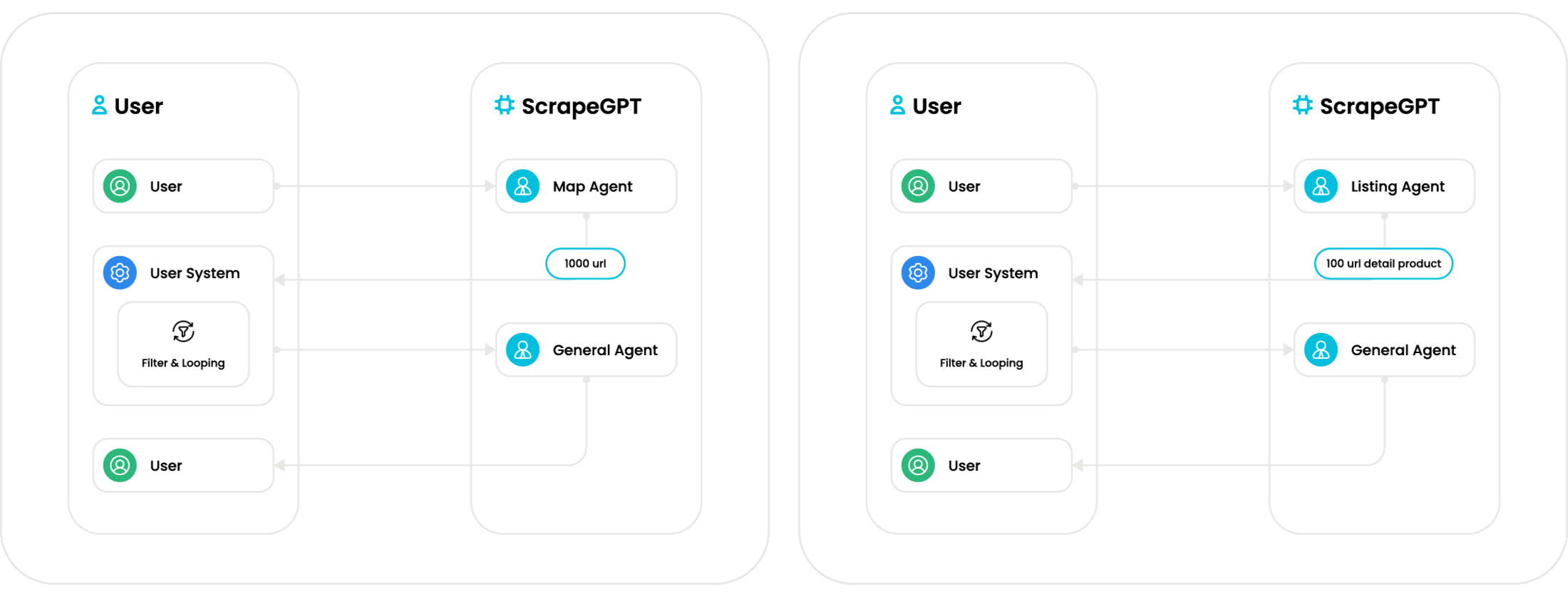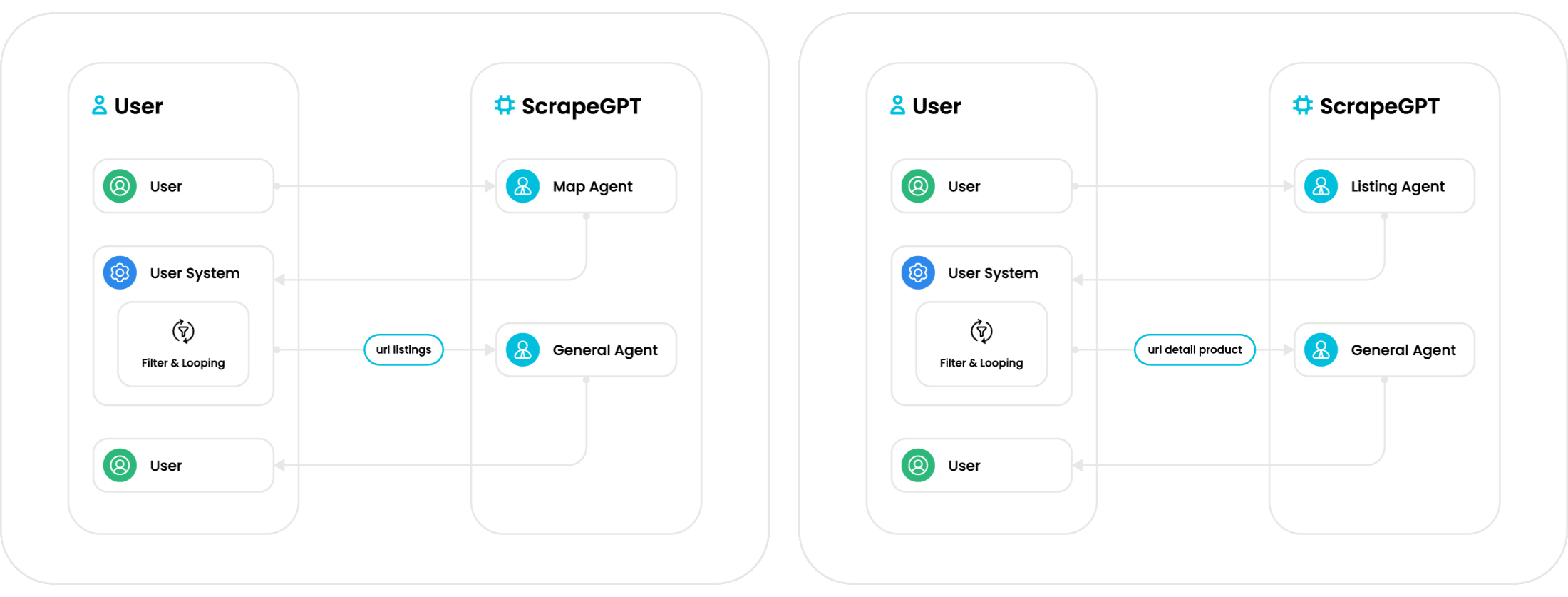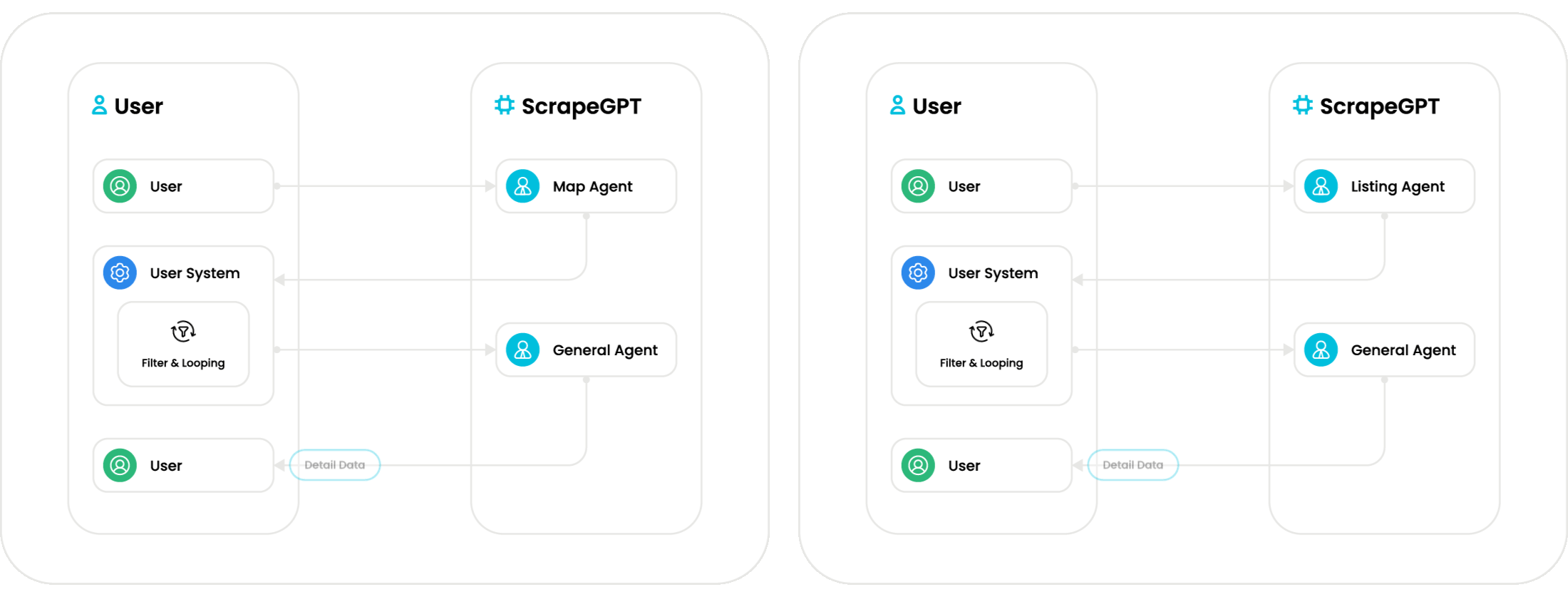 Mrscraper Agent is built around a directed acyclic graph (DAG) pipeline, where each agent operates as a deterministic stage with clear inputs and outputs. The goal is straightforward: map the domain, identify listing structures, and extract structured data—without relying on guesswork or non-deterministic agent loops.
Mrscraper Agent is built around a directed acyclic graph (DAG) pipeline, where each agent operates as a deterministic stage with clear inputs and outputs. The goal is straightforward: map the domain, identify listing structures, and extract structured data—without relying on guesswork or non-deterministic agent loops.
With the available agents, you can build a complete end-to-end scraping system. As illustrated in the flow above, Mrscraper Agent supports two deterministic data paths: (1) starting from a seed domain using the Map Agent and General Agent to discover and extract listing or product URLs; and (2) starting from a listing page URL using the Listing Agent and General Agent to iterate through listing items and extract detailed product data.
1. Map Agent — Domain Mapping & URL Discovery
The Map Agent is responsible for understanding the structural layout of a website at scale. It performs controlled crawling to discover all relevant subdomains, listing-page URLs, and detail-page URLs that serve as the foundation for downstream extraction.
Engineering Approach
-
Seed Initialization Start from a root URL (e.g., https://example.com) and automatically detect additional subdomains or related entry points that belong to the same domain space.
-
BFS Traversal & Per-Page Processing Apply a breadth-first traversal to explore the domain evenly and avoid over-crawling any deep branch. Each fetched page is then lightly processed to keep only useful navigable links while filtering out anything irrelevant or redundant.
Output
A clean, deduplicated map of all discovered subdomains, all listing pages, and all URLs that directly or potentially lead to detail/product pages.
2. Listing Agent — Extracting Listing
Within a domain, pages often share similar listing structures, but their behaviors can vary dramatically. Some sites use simple static HTML, while others rely on lazy-rendered content, infinite scroll, load-more buttons, next-page pagination, or dynamic SPA behavior.
The Listing Agent understands these behaviors and adaptively navigates them to collect all relevant listing data and their corresponding URLs.
Engineering Approach
-
Environment Observation
Analyze how the website loads and reveals content. This includes detecting:- Static vs. lazy-rendered content
- Infinite scroll behavior and when to scroll gradually
- “Load More” / “Show More” button interactions
- Next/Previous pagination patterns
- Client-side rendering (SPA) that requires controlled interaction
With this understanding, the agent determines how to interact with the page—scrolling slowly, clicking load triggers, or stepping through pagination—to ensure every item is captured.
It can scroll the page, trigger next-page navigation, click load-more elements, or perform other interactions autonomously—mimicking how a human would explore the listings until all items are fully loaded. -
Pattern Localization
Detect repeated visual or structural blocks (cards, rows, grids) that represent item listings, even when layouts differ across sections of the same site. -
Caching Behavior
Preserve behavioral insights and structural patterns so subsequent runs can skip re-analysis and operate with higher efficiency.
Output
All listing data on the page, along with their corresponding detail-page URLs—collected reliably regardless of how the site renders or loads its content.
3. General Agent — Data Extraction for Any Targeted Page
The General Agent extracts user-requested fields from any targeted page, whether it is a listing page or a detailed product page. Extraction is performed based entirely on the user’s prompt, allowing flexible and precise data retrieval for any page structure.
Engineering Approach
-
Page Layout Analysis
Analyze how the page is structured, including visible UI elements and the underlying DOM, to understand how content is presented on both listing and detail pages. -
Field Identification
Identify and extract every field requested by the user—whether it comes from a product detail section, a listing card, or other structured/unstructured content. The agent can also retrieve non-visible data such as values stored in "script" tags, embedded JSON, metadata, or hidden HTML attributes—ensuring complete coverage even when information does not appear directly on screen.
Output
A structured dataset containing all user-requested fields extracted from the targeted page—whether that page represents a listing, a collection of items, or a detailed product view.
Cached Behavior
On subsequent runs against the same domain, Mrscraper Agent loads the cached specification instead of re-analyzing the structure, reducing both latency and cost.
Why Mrscraper Agent Uses Multiple Specialized Agents and directed acyclic graph approach
When we first started designing Mrscraper Agent, our initial idea was to use a single autonomous agent that could do everything: explore the domain, find the listings, open each detail page, and extract the data. The idea was simple, just to give an AI a URL and let it figure everything out on its own—clicking, scrolling, and deciding where to go next, just like a human would.
While a fully autonomous loop sounds great on paper, in practice, it was slow, expensive, and unreliable. The agent would often get "distracted," spending too much time processing irrelevant pages, getting stuck in navigation loops, or hallucinating the site structure. It was slow, costly, and hard to debug.
After several rounds of prototyping, testing with real client websites, and a lot of trial and error, we learned a few things:
- Looping agents are good at reasoning, but bad at staying focused.
- Different parts of a scraping workflow require very different skill sets.
- Most client use cases don’t need a “fully autonomous explorer.” They just need reliable extraction that works in seconds.
As these insights became clearer, it was evident that relying on a single looping agent was fundamentally limiting. What we needed wasn’t more autonomy, but more structure. This led us to redesign Mrscraper Agent around a coordinated set of specialized agents connected through a directed acyclic graph (DAG). Instead of one agent trying to manage every decision in real time, each stage now has a precise role, clear boundaries, and deterministic execution. This shift transforms scraping from an open-ended exploratory loop into a predictable, reliable pipeline. The advantages of this architecture become especially clear in the areas below.
1. Deterministic Behavior & Failure Isolation
Loop-based agents often fall into unpredictable states such as infinite loops, oscillation, or cascading failures.
The DAG pipeline ensures:
- Bounded execution time — each stage has defined termination
- Predictable costs — tokens scale with input size, not agent drift
- Fault isolation — failures in one stage don’t corrupt others
2. Specialized Optimization
Each agent is optimized for a focused responsibility:
-
Map Agent
Efficient domain crawling (BFS + deduplication), discovering all subdomains and URL patterns without performing extraction. -
Listing Agent
Detects listing structures, pagination behavior, dynamic-loading patterns, and collects all listing URLs—without reasoning about fields. -
General Agent
Extracts any user-requested fields from any targeted page (listing or detail), without dealing with navigation or crawling.
This separation yields stronger accuracy, less confusion between tasks, and faster performance across the entire pipeline.
3. Task-Aligned Decision Making
Scraping workflows follow a predictable sequence:
explore → collect listings → extract details.
The DAG encodes this sequence directly. Each agent makes intelligent decisions only within its scope—removing guesswork and reducing hallucinations that usually occur in multi-step autonomous systems.
4. Reusability & Caching
The linear pipeline enables powerful caching. Each stage produces reusable outputs that can be loaded instantly on future runs for the same domain:
- Map Agent → complete URL map (subdomains, listing pages, detail pages)
- Listing Agent → detected listing patterns + list of item URLs
- General Agent → extraction schema + structured results
These artifacts are versioned and stored, enabling Mrscraper Agent to reuse domain knowledge and skip unnecessary inference.
For previously scraped domains, extraction can run with zero added AI cost, making the system dramatically faster and cheaper over time.
5. Human-in-the-Loop Friendly
The DAG introduces validation checkpoints that make Mrscraper Agent easy to supervise and tune at every stage—ensuring accuracy, eliminating wasteful crawling, and giving you full control of the pipeline.
Map Agent — Review and Filter the Domain Map Early
Once the domain is crawled, the Map Agent outputs a complete map of discovered URLs, including subdomains, listing pages, and potential detail pages.
At this step, the user can:
- Filter which URLs should or should not be processed
- Include or exclude paths, patterns, or subdomains
- Narrow the crawl to specific URL structures (e.g.,
/product/,/shop/,/listing/) - Remove pages that contain irrelevant content
This is particularly useful because some URLs may contain both listings and detail-product links.
User-side filtering lets you shape exactly which URLs move forward to Listing Agent or directly to General Agent.
Early validation ensures only relevant URLs move to the next stages—reducing cost, time, and noise.
Listing Agent — Confirm Listing Structure
Before scraping all listing pages, Mrscraper Agent provides an accurate preview of how listing elements were detected.
You can verify:
- Whether listing blocks were correctly identified
- Titles, prices, images, labels, and metadata
- Pagination, infinite scroll, or load-more behavior
- Whether the listing URLs are the correct ones to process at scale
This ensures the listing logic is correct before batching thousands of pages, and allows you to refine which listing URLs should be forwarded to the next stage.
General Agent — Fine-tune Extraction Fields
On the first run of any targeted page, the General Agent generates a preview of extracted fields.
You can then prompt to:
- Add new fields
- Remove unnecessary fields
- Rename fields
- Correct extraction logic
- Request hidden data (e.g., JSON, metadata, script content)
This refinement step ensures your extraction schema is perfect before scaling to thousands of pages—without writing or editing any code.
How Mrscraper Agent Compares to Other Web Scraping Platforms
Modern AI-driven scraping platforms vary widely in their architectural assumptions, navigation capabilities, and output quality. Some tools prioritize raw speed, while others focus on extraction accuracy or search-oriented use cases. Mrscraper Agent, however, is designed specifically for large-scale structured data extraction, combining deterministic agents with adaptive browser-level interaction and reusable domain history to produce consistent and reliable outputs.
A major differentiator is how Mrscraper Agent processes raw HTML. While tools like Firecrawl often return low-level scraped content—such as raw HTML or minimally parsed text, Mrscraper Agent applies a specialized extraction pipeline that converts each page into clean, structured, and high-fidelity datasets, eliminating the need for extensive post-processing.
While several modern AI scraping tools have emerged, Mrscraper Agent further distinguishes itself through specialized agents, deterministic pipelines, and human-in-the-loop checkpoints. Here's a quick comparison of Mrscraper Agent against other popular tools on website www.Zillow.com :
| Platform | Core Features | Map Scraping | Listings Scraping | Detail Scraping | Adaptive Navigation System | Precision |
|---|---|---|---|---|---|---|
| Mrscraper | General Scrape, Map Scrape, Listing Agent, History Cache | ✔️ | ✔️ | ✔️ | ✔️ | High |
| Firecrawl | General Scrape, Map Scrape, Crawl, Search-like Query | ✔️ | ✔️ | ✔️ | ❌ | Medium |
| Exa.ai | Search-like Query | ❌ | ❌ | ❌ | ❌ | Low |
| Browserbase | Single Page Scrape, Auto Code Generation | ❌ | ❌ (Failed on CAPTCHA) | ✔️ | ❌ | High |
Mrscraper Agent provides a more complete and purpose-built scraping solution compared to alternative platforms, especially when the objective is to extract structured data at scale. Its multi-agent architecture—consisting of a Map Agent, Listing Agent, and General Agent, enables it to manage end-to-end workflows that would normally require complex custom automation. Unlike Firecrawl, which aims for broad and generalized extraction, Mrscraper Agent emphasizes precision, determinism, and repeatability, supported by history caching for cost-efficient re-runs within the same domain. Meanwhile, Exa.ai and Browserbase serve narrower use cases, Exa.ai is focused on search-style queries, and Browserbase offers page-level automation but struggles with stability and speed. Overall, Mrscraper Agent stands out as the strongest option for users needing accurate, structured, and scalable web data extraction.
By enabling inspection, sampling, and easy schema adjustments, Mrscraper Agent supports progressive validation—a workflow that mirrors how production-grade data pipelines are normally monitored. The Map Agent, Listing Agent, and General Agent each provide just the right specialization, while AI-generated specifications eliminate the traditional burden of maintaining custom scraper code.
Find more insights here

How to Scrape Websites Without Getting Blocked: A Complete Guide
A complete guide to scraping websites without getting blocked — proxy rotation, browser fingerprinti...

Web Scraping API Guide: How They Work and When to Use One
A complete guide to web scraping APIs — how they work, the different types, when to use one vs. buil...

How to Scrape Multiple Pages With a Web Scraping API (Step-by-Step Guide)
Learn how to scrape multiple pages with a web scraping API — handling URL, offset, cursor, and JavaS...
