
How to Scrape Tamilyogi: A Simple Guide Using MrScraper
GuideScraping Tamilyogi can be a valuable tool for data extraction, allowing you to gather information in a structured format for personal use or analysis. Step-by-Step Guide to Scrape Tamilyogi with MrScraper: 1. Sign up for Mrscraper 2. Create a scraper 3. Create the workflows 4. Add paginations (Optional) 5. Run the scraper 6. Export data
Tamilyogi is a popular site for streaming and downloading Tamil movies, TV shows, and other content. While the site offers vast content, users might find it challenging to organize or extract specific data for personal use or analysis. This is where web scraping comes in handy. In this tutorial, we will guide you through the process of scraping Tamilyogi using MrScraper, a powerful web scraping tool that makes the task simple and efficient.
What is Web Scraping?
Web scraping is the process of extracting data from websites. It involves using a tool or software to automatically access a webpage, retrieve its content, and store it in a structured format like CSV, JSON, or a database. Scraping can be used for various purposes, including data analysis, content aggregation, and even SEO research.
Why Scrape Tamilyogi?
There are several reasons why someone might want to scrape Tamilyogi:
- Content Aggregation: Collecting a list of all movies or TV shows available on the site.
- Metadata Extraction: Extracting information like movie titles, release dates, genres, and ratings for cataloging or personal use.
- Data Analysis: Analyzing trends in Tamil cinema based on the content available on Tamilyogi.
Step-by-Step Guide to Scrape Tamilyogi with MrScraper
Step 1: Sign up for Mrscraper
First, sign up for an account on MrScraper to use the scraping application. You can sign up with an email address or login via Google or Github. Once an account is created and verified, you can now access the scrapers.
Step 2: Create a scraper
Next, create a scraper for Tamilyogi. To create a scraper, go to the scrapers tab then click Manual Scraper. Enter the name with anything you like, select the type Standard, then enter the Default entry URLs with the Tamilyogi website containing the movie list. For example: https://tamilyogi.city/category/tamilyogi-full-movie-online
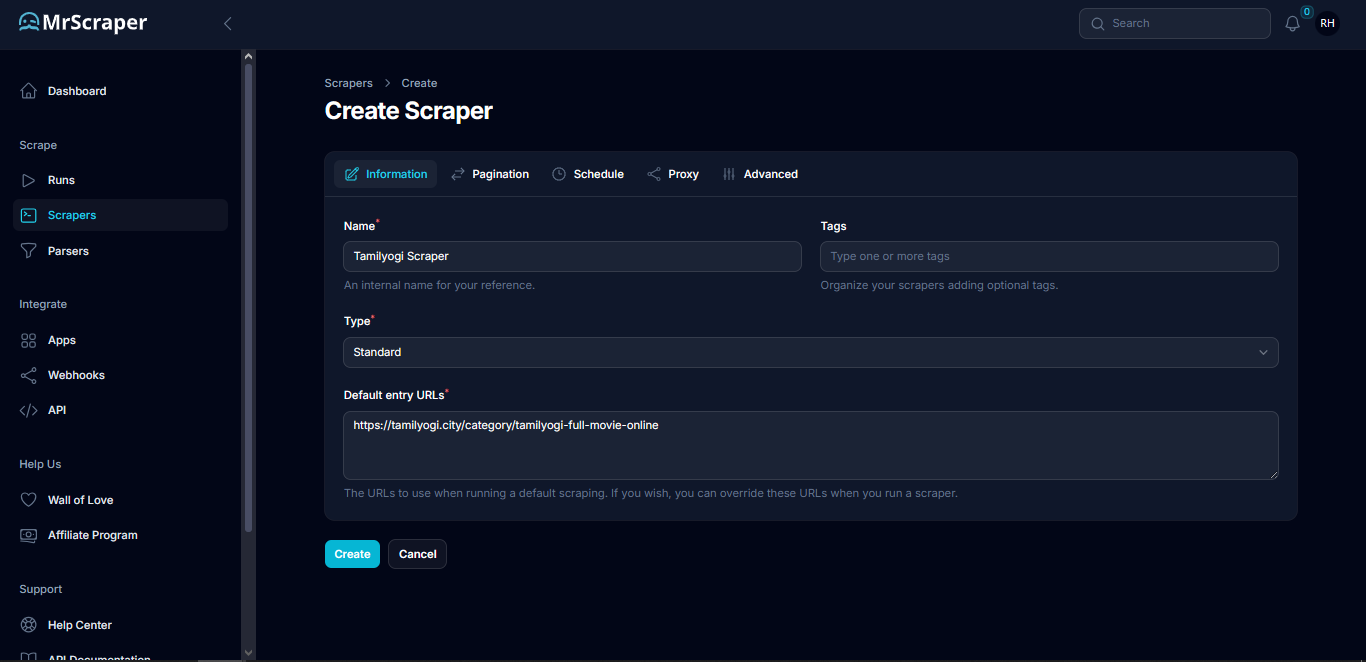
Step 3: Create the workflows
Next we need to create workflows for the scraper. Before creating a workflow, you need to know how the Tamilyogi website is displaying the data and how to choose the right selector for the data you want to scrape.
To find the selector for the data, you need to use your browser’s Devtools Inspect Element on the website you want to scrape and click the Elements tab to view the HTML elements of the page.
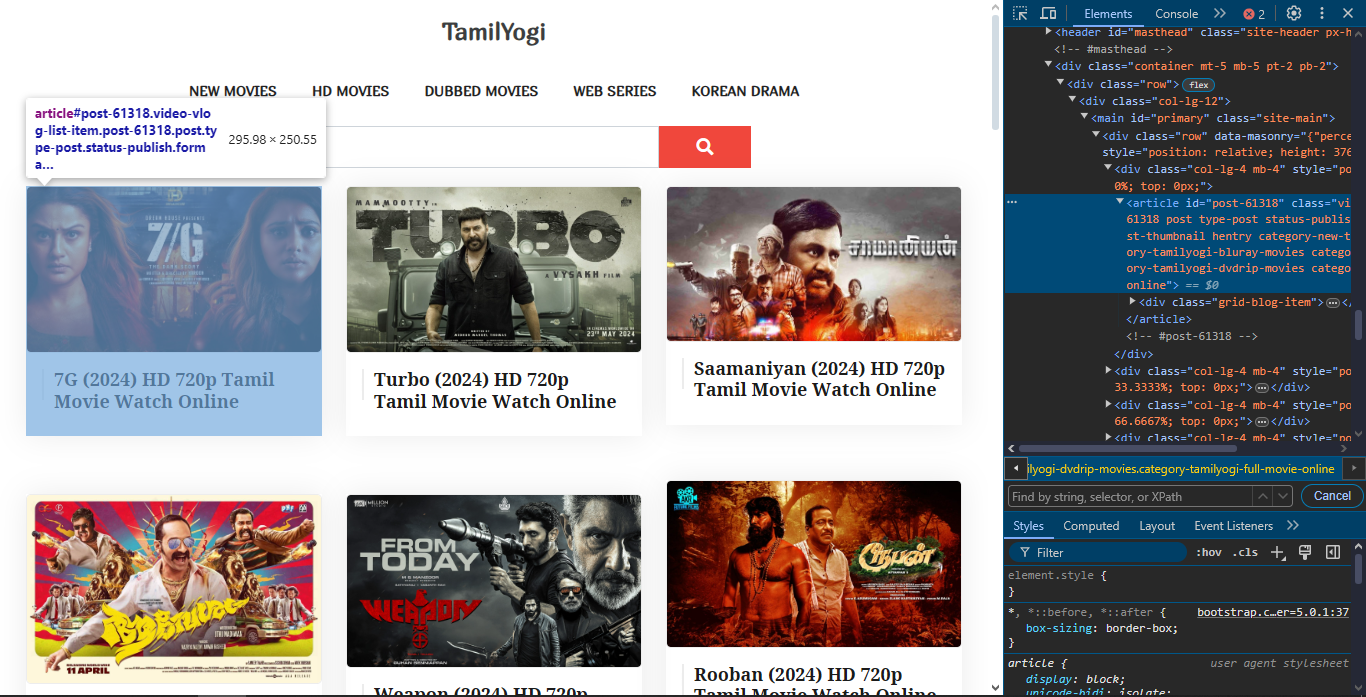 First, find the element containing the data for each of the movies. In the image above, we can see that the element “article” with the class “post” contains the data for the movie so the selector for the element is “article.post”.
First, find the element containing the data for each of the movies. In the image above, we can see that the element “article” with the class “post” contains the data for the movie so the selector for the element is “article.post”.
Next, we create a workflow by clicking the Add step button and then choosing Scrape data. Fill the name with anything you want, then choose Collection for the type, and then choose All matches for the quantity to scrape all the data in the page with the same selector. For the selector, choose the CSS type then fill the parent selector with the selector we got which is “article.post”.
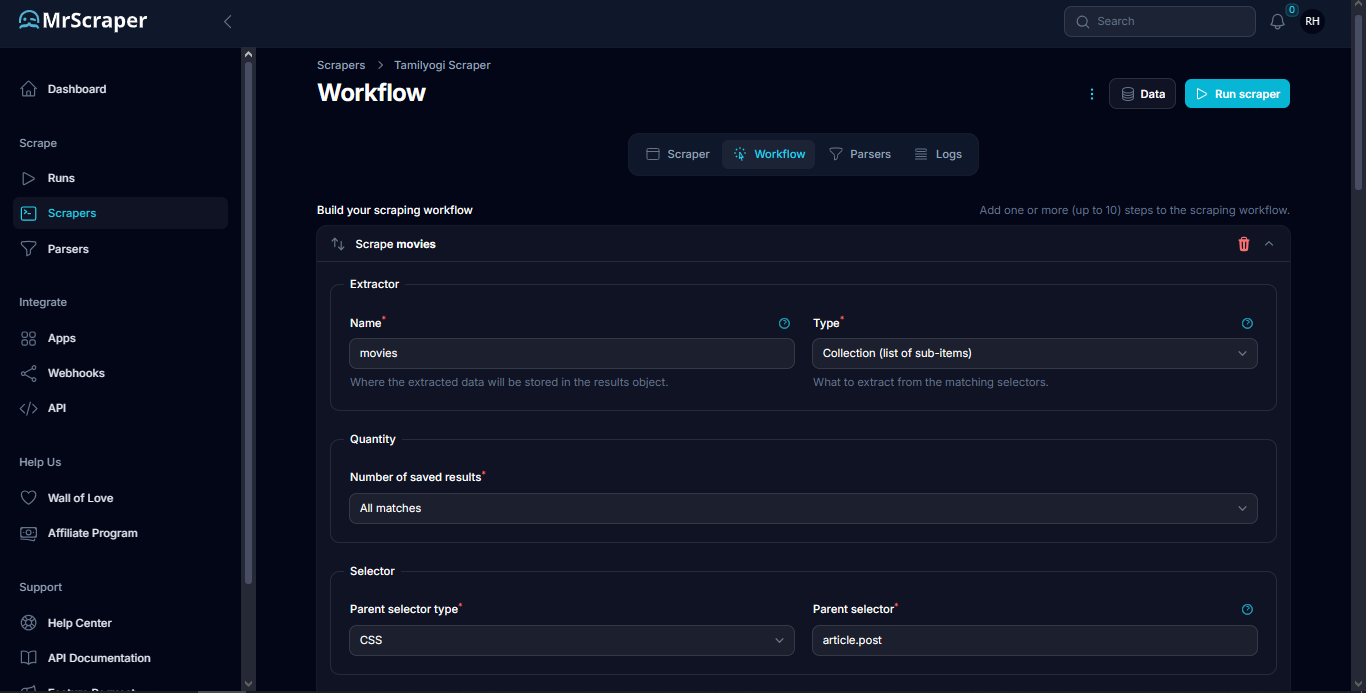 Then, we need to determine the data fields we want to scrape from each of the movies. In this example, we are going to scrape the name, url, and the image url.
Then, we need to determine the data fields we want to scrape from each of the movies. In this example, we are going to scrape the name, url, and the image url.
Same as the parent selector, we need to find the selector for each of the data fields. Add a collection item for each of the data fields.
- name:
.entry-titleChoose the type Text for this field. - image:
imgChoose the type Attribute for this field, fill the attribute with “src” - url:
aChoose the type Attribute for this field, fill the attribute with “href” Choose the First match quantity for every field.
Save the workflow then we’re ready to run the scraper.
Step 4: Add paginations (Optional)
To be able to scrape data from multiple pages, you can add paginations to your scraper. Go to the scraper tab then click the pagination tab. Enable the pagination scraper, then choose the pagination type of the web. In this example, we will be using the Next page link with the selector a.next and optionally, limit the amount of pages you want to scrape.
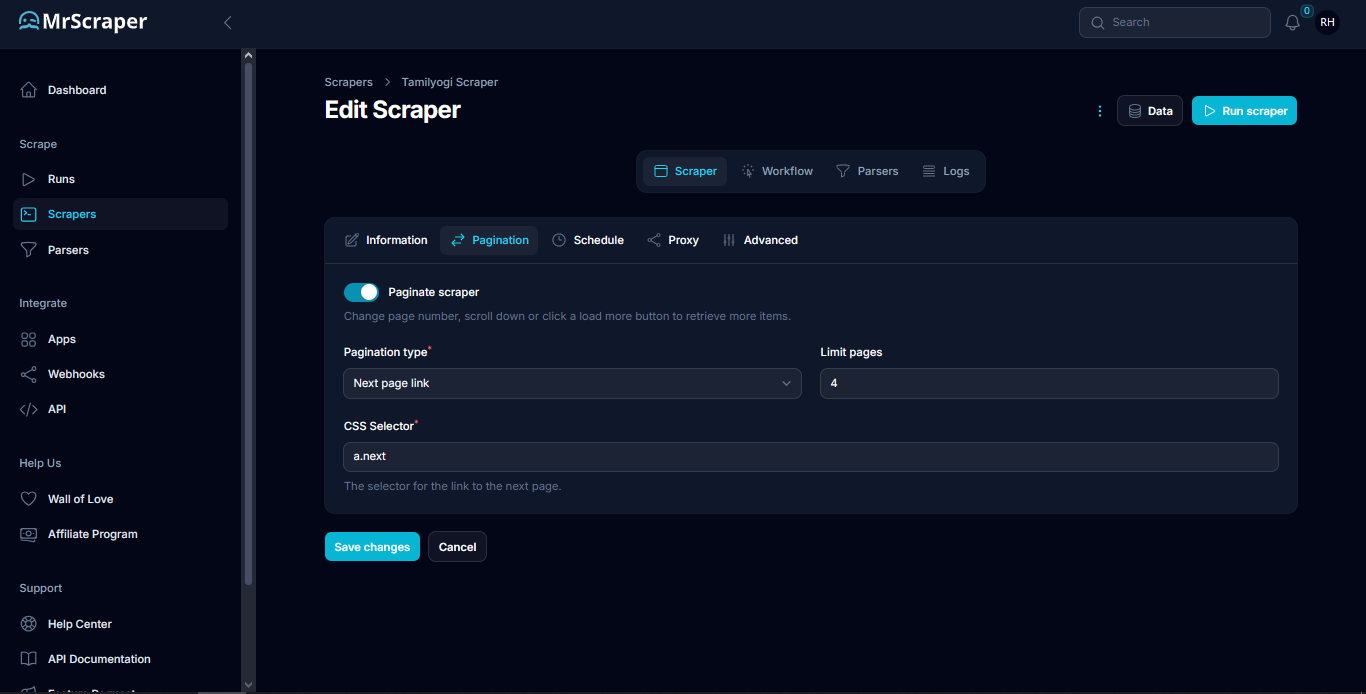
Step 5: Run the scraper
To run the scraper, click the Run scraper button on the top right then choose Default run.
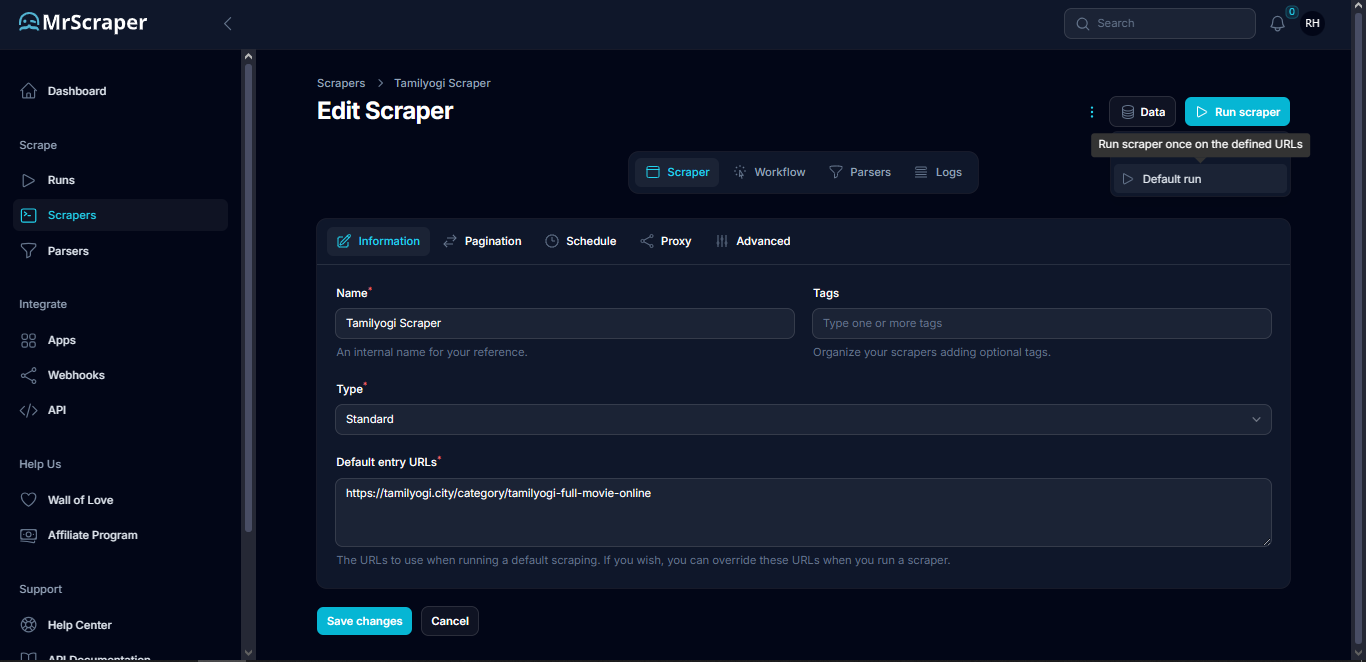 After running the scraper, we can now wait until the scraping process is complete, it usually takes around 30 seconds based on the website and the workflows.
After running the scraper, we can now wait until the scraping process is complete, it usually takes around 30 seconds based on the website and the workflows.
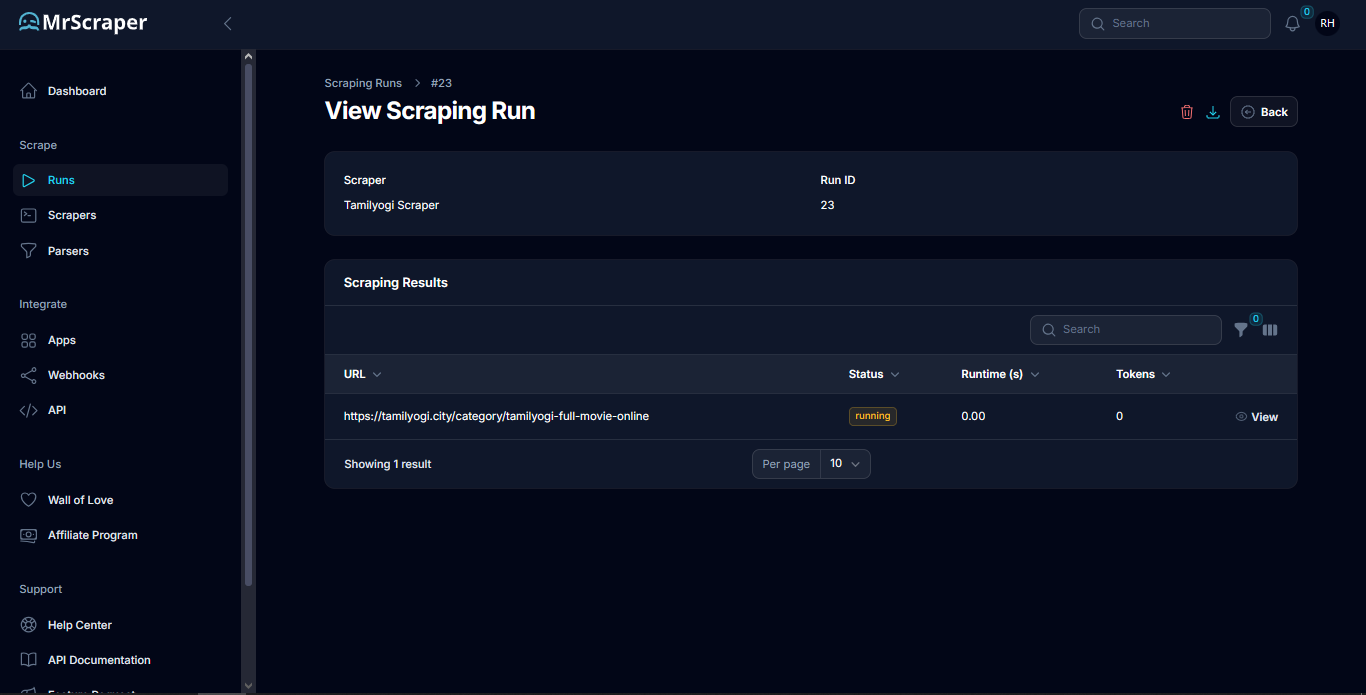
Step 6: Export data
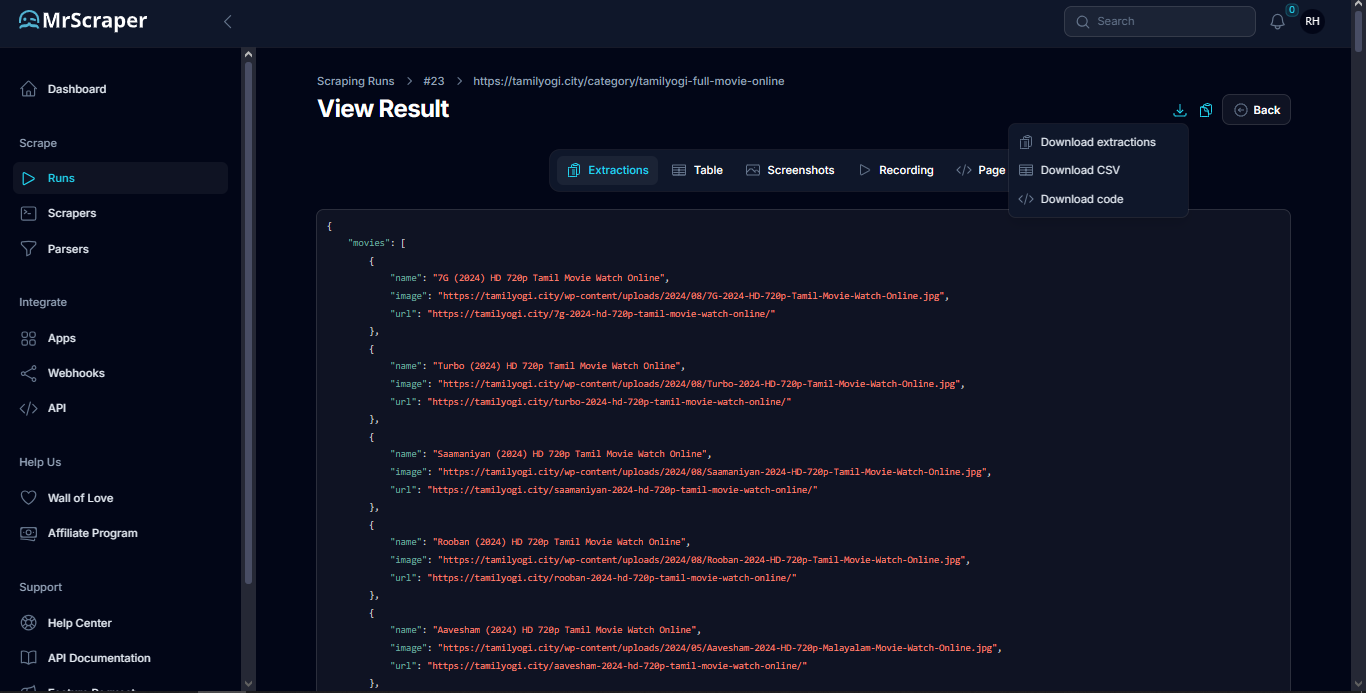
Lastly, after the scraping process is complete, you can view and export the result which you can copy or download the extracted data in JSON or CSV format.
Is Scraping Tamilyogi Legal?
Before you start scraping, it’s important to consider the legality and ethical implications. Scraping copyrighted content or using the data for commercial purposes without permission can lead to legal consequences. Always ensure that your scraping activities comply with local laws and the website’s terms of service.
Conclusion
Scraping Tamilyogi can be a valuable tool for data extraction, allowing you to gather information in a structured format for personal use or analysis. With MrScraper, the process becomes easy and efficient, even for those with minimal technical skills. Always remember to use scraping responsibly and within legal boundaries.
Find more insights here

How to Extract Data From Pop-ups and Modals Using a Scraping Browser
Learn how to extract data from pop-ups and modals using a scraping browser — detecting triggers, wai...

How to Use a Web Scraping API for Lead Generation at Scale
Learn how to use a web scraping API for lead generation — building B2B prospect lists from public di...

How to Schedule Automated Web Scraping Jobs (Step-by-Step Guide)
Learn how to schedule automated web scraping jobs using cron, APScheduler, cloud schedulers, and no-...
