
How to Scrape Google Scholar: Step-by-Step Using MrScraper
GuideGoogle Scholar hosts a wealth of academic papers, citations, and research publications. By scraping this data, you can collect and analyze academic trends, build a research database, and extract citation data for in-depth analysis.
Scraping data from Google Scholar can be invaluable for researchers, students, and data enthusiasts looking to compile comprehensive academic information. In this guide, we’ll walk you through the step-by-step process of scraping Google Scholar using MrScraper, a powerful and reliable web scraping tool.
Why Scrape Google Scholar?
Google Scholar hosts a wealth of academic papers, citations, and research publications. By scraping this data, you can:
- Collect and analyze academic trends.
- Build a research database.
- Extract citation data for in-depth analysis.
Is It Legal to Scrape Google Scholar?
Before diving in, it’s important to ensure compliance with Google Scholar’s terms of service and ethical guidelines. Make sure that your scraping activities don’t violate their policies or overload their servers.
Step-by-Step Guide to Scraping Google Scholar with MrScraper
1. Sign Up for MrScraper
If you’re new to MrScraper, start by creating an account on the MrScraper website. The platform is intuitive and straightforward, ideal for extracting data without any coding requirements.
2. Visit the News Website
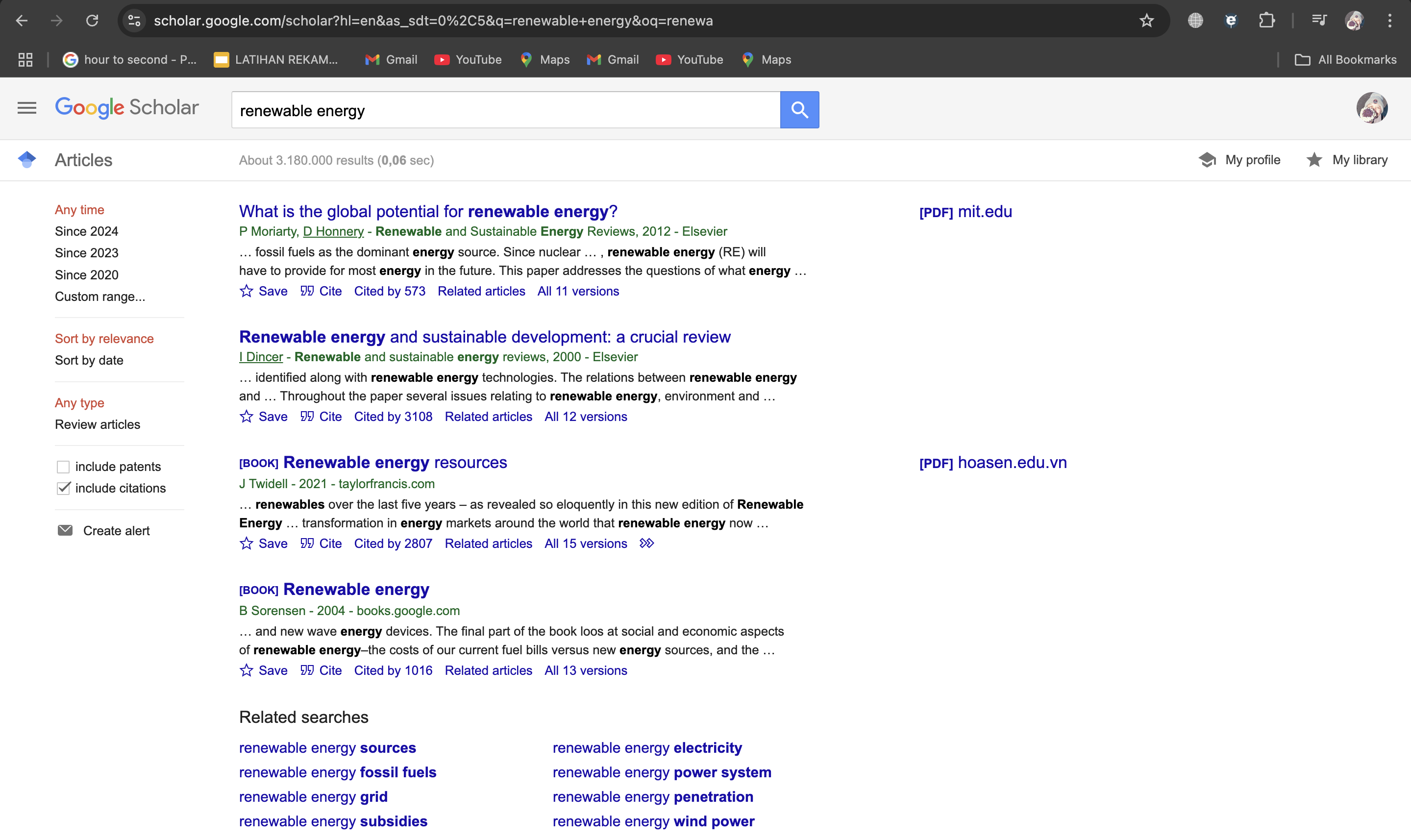
Next, head to the news website you want to scrape. For example, if you’re interested in renewable energy research and citations, type the topic you want to scrape in the search bar. Copy the URL of the section or page you’d like to scrape, as you’ll need it in the next step.
3. Configure MrScraper for the Google Scholar Website
Once you’re logged into MrScraper, go to the home page and create a new scraping project. In the project setup, paste the URL of the news website into the ScrapeGPT feature. This tells MrScraper where to gather data from. Make sure you’re using a URL that targets the specific section you’re interested in. In this case, we use this URL “https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=renewable+energy&oq=renewa”
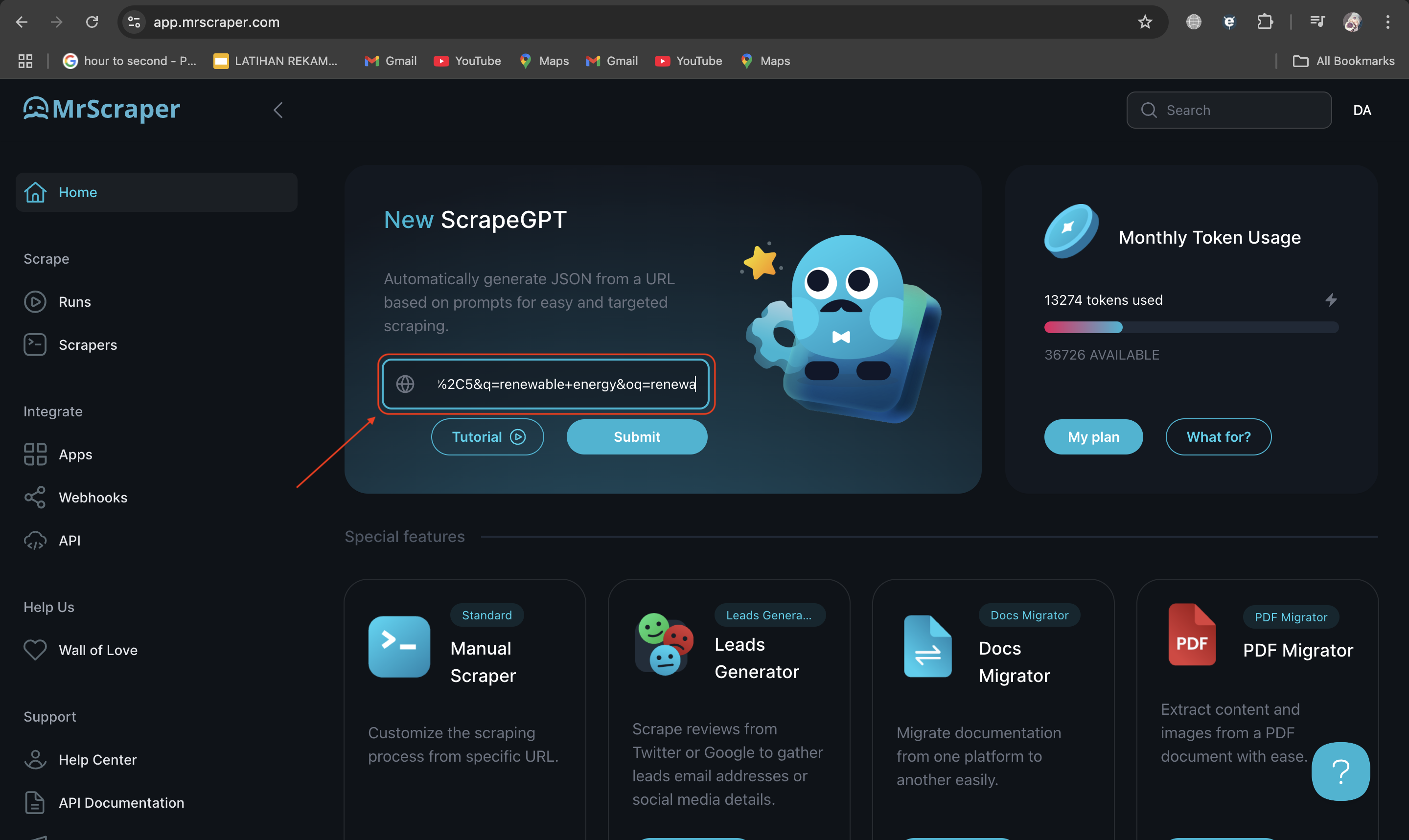
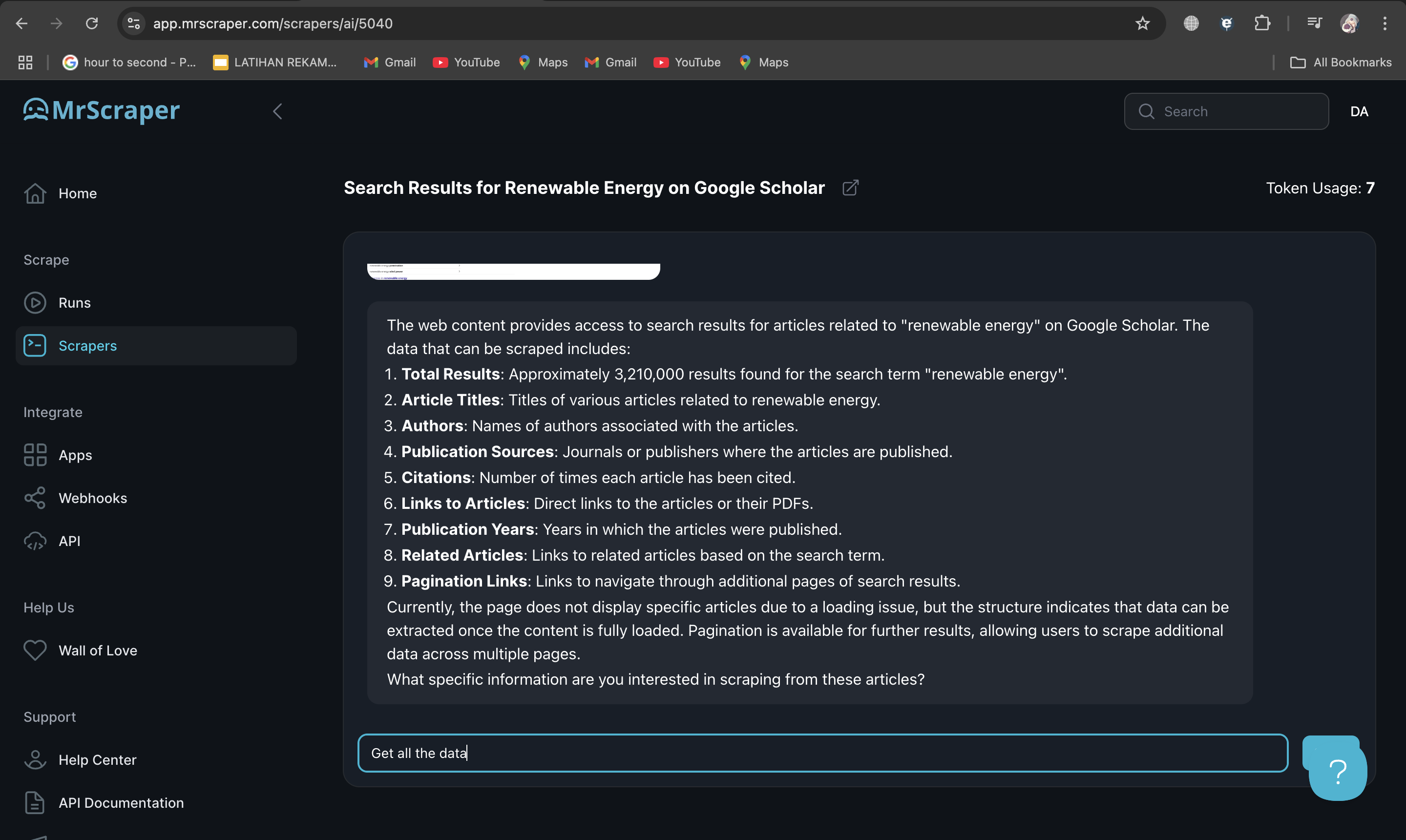
4. Allow ScrapeGPT to Load and Enter the Prompt
After loading the news site’s page within MrScraper, type the prompt “Get All the Data” to instruct ScrapeGPT to extract the available listings or articles. This will initiate the scraping process, where MrScraper begins gathering information such as headlines, publication dates, and article content.
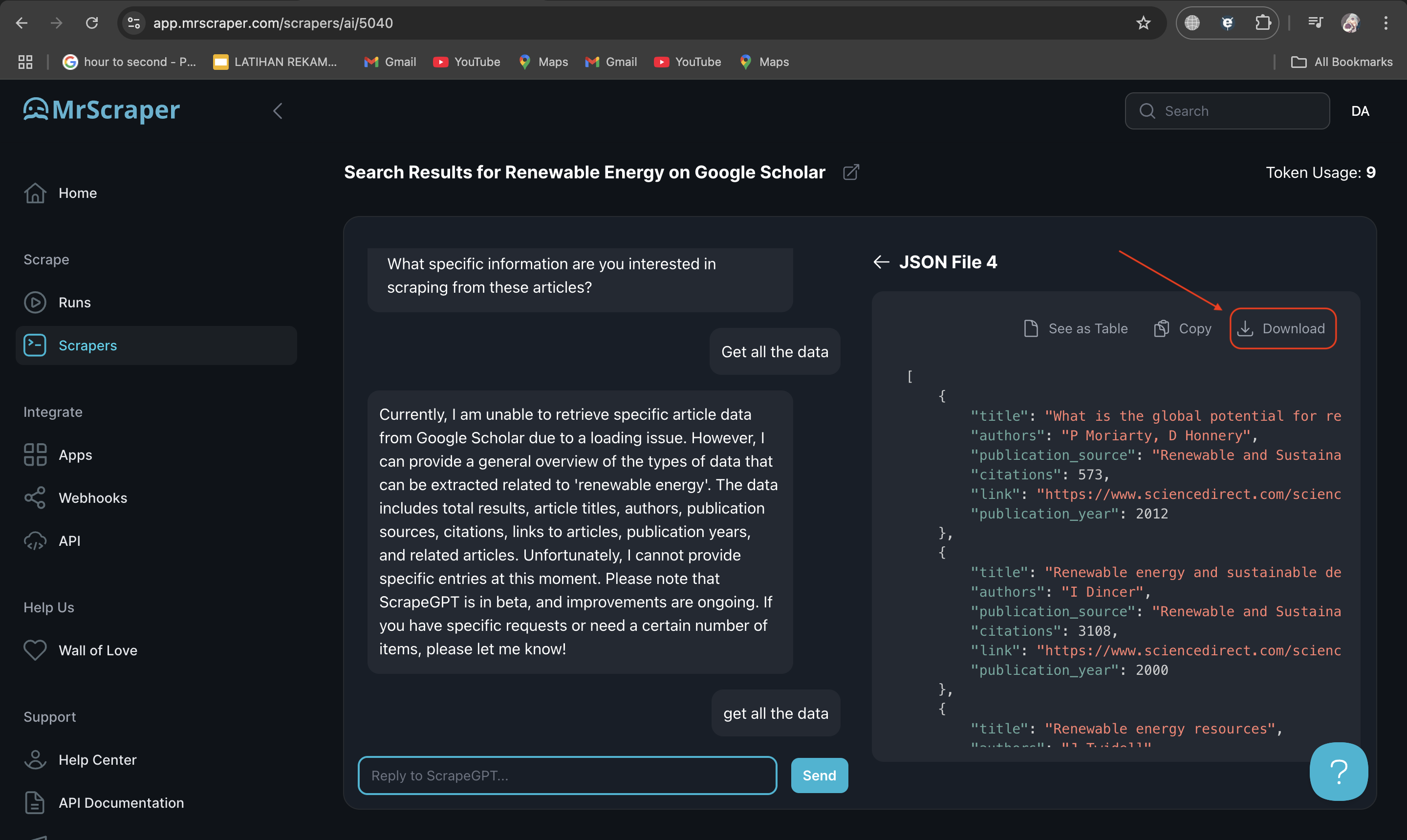
5. Review and Download Your Data
Once ScrapeGPT completes the data extraction, you can review the results directly in MrScraper to ensure you have the information you need. When satisfied, download the data in either JSON or CSV format. These formats make it easy to analyze, organize, or integrate the data into your workflow.
Tips for Effective Google Scholar Scraping
- Use Proxies: Google Scholar may block repeated requests from the same IP address. Utilize proxies or MrScraper’s IP rotation feature to avoid being blocked.
- Rate Limiting: Implement rate limits to make your scraping more human-like and reduce the chance of detection.
- Fast and Safe: If you are scraping using MrScraper, rest assured that it is already optimized for speed and safety, minimizing the risks of detection.
- Respect Robots.txt: Always verify Google Scholar’s
robots.txtfile and adhere to the limitations stated there.
Conclusion
Scraping Google Scholar using MrScraper provides a powerful way to gather academic data efficiently. By following this guide, you’ll be able to collect valuable insights while maintaining best practices for responsible web scraping.
Start your data extraction journey with MrScraper and explore the world of academic research with ease!
Find more insights here

AI Web Scraping: The Complete Guide to Intelligent Data Extraction
A complete guide to AI web scraping — how LLMs enable selectorless data extraction, schema-driven ou...

Browser Automation for Web Scraping: Tools and Best Practices
A complete guide to browser automation for web scraping — Playwright, Puppeteer, Selenium compared,...

How to Scrape Websites Without Getting Blocked: A Complete Guide
A complete guide to scraping websites without getting blocked — proxy rotation, browser fingerprinti...
