guide How to scrape data from a website using no-code
In this article, we will take you through the steps to use MrScraper to scrape data from any website. We will cover everything from setting up your scraper to integrating it with your favorite tools.
Table of contents
What is web scraping?
Imagine that you want to extract a list of product prices and descriptions from an online store. Instead of manually copying and pasting each piece of information, which can be very time-consuming, you can use a web scraping tool to automate the process. The scraping tool will analyze the HTML code of the web page, identify the location of the data you're looking for, and extract it automatically.
Web scraping can be utilized for many purposes, such as market research, data analysis, or building a database. It's a powerful tool that can save time and effort by automating repetitive tasks that would otherwise require a lot of manual work.
It's important to use web scraping tools responsibly and to always respect the terms of use of the websites you're scraping data from.
What is MrScraper.com
MrScraper is a no-code tool that allows you to scrape data from websites without any programming knowledge. It is user-friendly, intuitive, and can be used by anyone, regardless of their technical background.
A tool like MrScraper is needed because web scraping can be a technically complex process that requires programming knowledge and skills. Traditionally, web scraping has been done using programming languages like Python, which require a certain level of technical proficiency to use effectively.
However, not everyone has the time, resources, or technical background to learn programming languages and build web scrapers from scratch. That's where no-code web scraping tools like MrScraper come in. They provide an easy-to-use interface that allows users to extract data from websites without any programming knowledge.
MrScraper's user-friendly and intuitive interface makes it accessible to anyone, regardless of their technical background. By simplifying the web scraping process, it eliminates the need for users to learn complex programming languages or spend hours manually extracting data from websites. With MrScraper, users can simply point and click to extract the data they require.
Overall, MrScraper and other no-code web scraping tools make web scraping more accessible to a wider range of users, allowing them to take advantage of the benefits of web scraping without the need for extensive technical knowledge or programming skills.
Scraping a website
To get you familiarized with the scraping workflow, we are going to build a simple web scraper that extracts all links from MrScraper's homepage.
Before we get started, make sure to get your MrScraper's FREE account.
1. Create a new scraper
Once you have your account ready, navigate to the “Scrapers” sidebar item.
You will see the list of all your scrapers. Currently, will be empty since you don't have any scraper created. Let's fix this by clicking the “New scraper” button in the top-right corner.
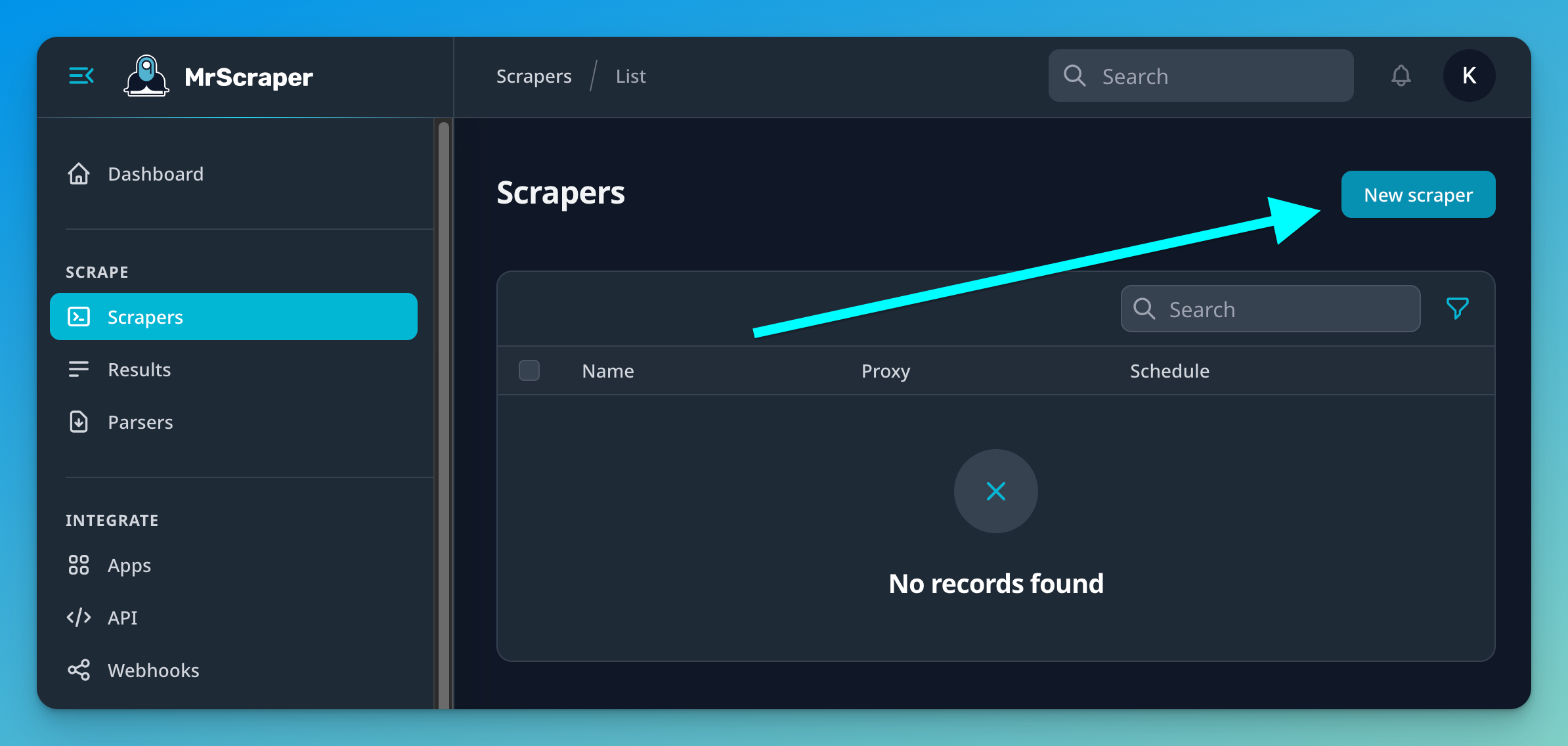
You will be redirected to the create Scraper form. This is a powerful builder that lets you visually make all kinds of web scrapers, with no code required!
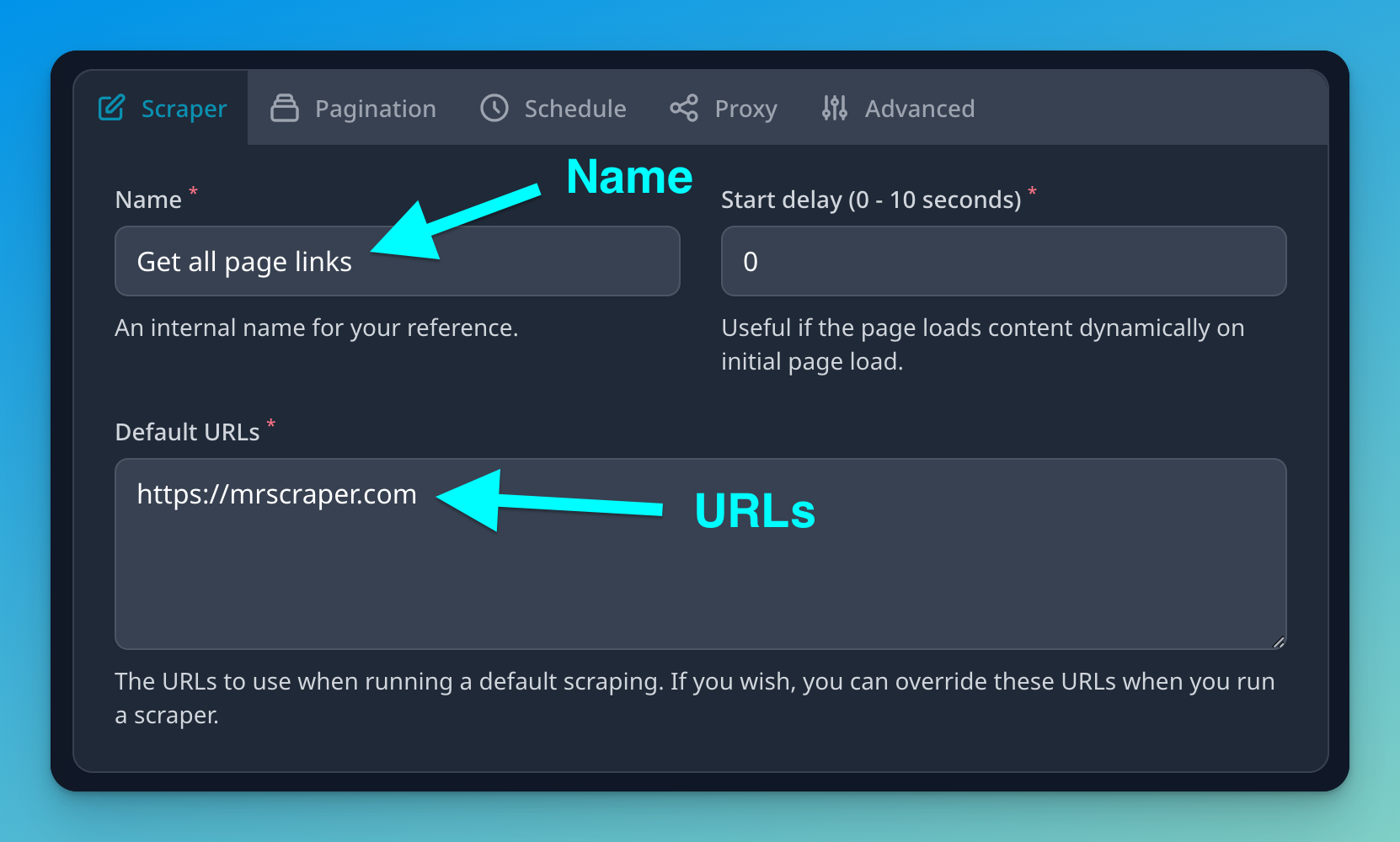
For this example, we are going to create a simple scraper. So let's fill in the basic information.
- Name: Add an internal name to this scraper. This name is for your reference only.
- Default URLs: The URLs or links that this scraper will scrape by default. If you are creating a scraper that needs to run on different URLs each time, you can override these URLs when running the scraper. Otherwise, the scraper will extract the information from these default pages.
2. Define extractors
The next step is to define what information we want to extract from those URLs or links.
In this example, we are building a simple scraper to get all the links from a web page. To achieve this, we will set the following items:
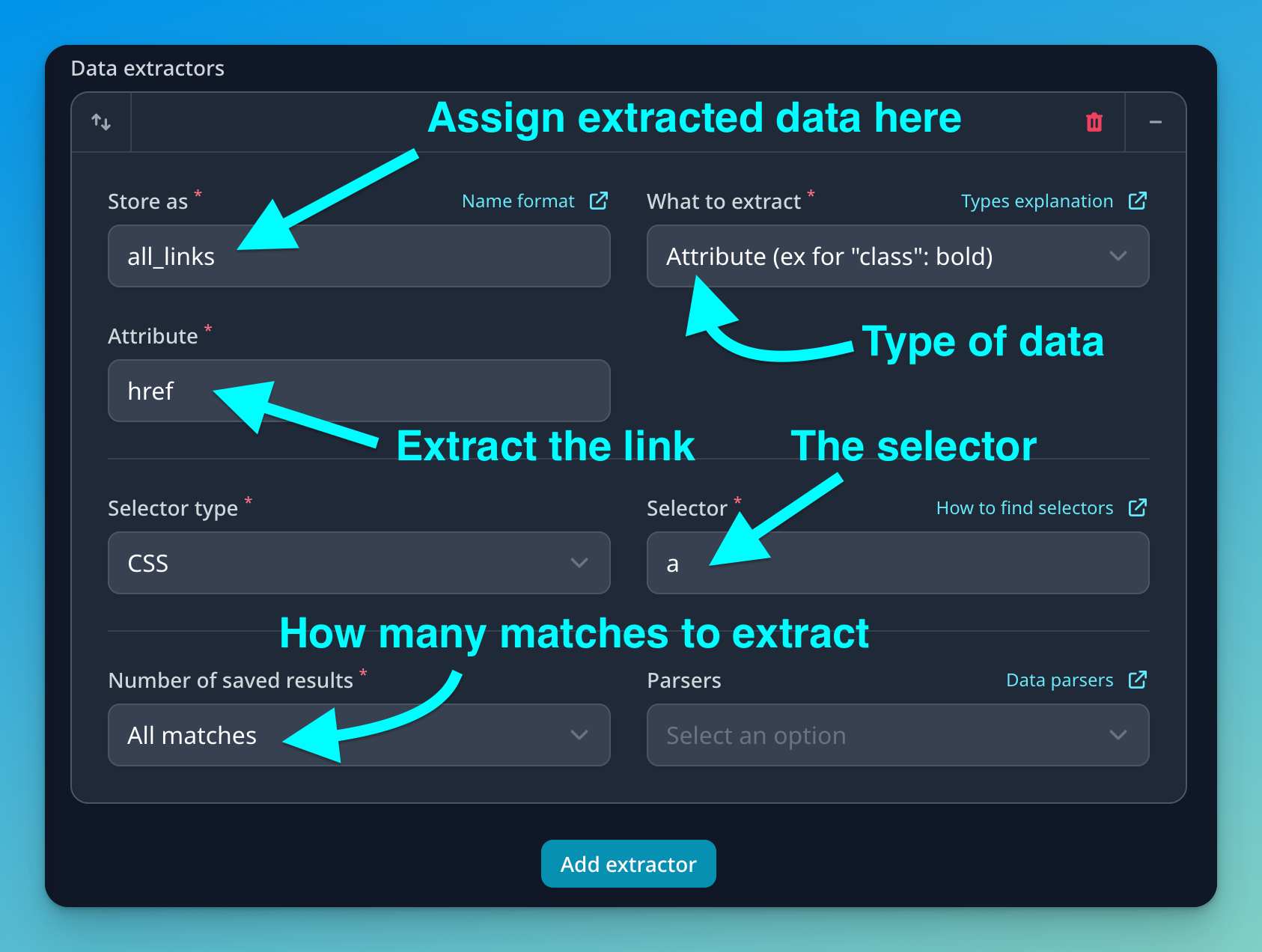
- Store as: The scraper is going to return the extracted data in JSON format. Don't panic, it's just a common format to store this kind of information. In this field, we are telling the scraper to put the information inside the property named “all_links”. This will make things easier at a later step once we want to retrieve or work with this information.
// example JSON of extracted data
{
"all_links": [
"https://mrscraper.com",
"https://mrscraper.com/blog",
"https://mrscraper.com/tools",
"https://mrscraper.com/login",
"https://mrscraper.com/register",
]
}
-
What to extract: This is where we tell the scraper what type of information is going to extract from the selected element. In this case, we aim to extract the links from the anchor tags:
<a href="https://mrscraper.com">. To accomplish this, we will use the “Attribute” option and specifically, we are going to get thehrefattribute. -
Selector type: We can define whether we want to use CSS or XPath selectors. If you are starting with scraping, stick to CSS selectors. We even have a Chrome extension to help you visually debug and craft CSS selectors from any website.
-
Selector: This is the selector itself, one of the key parts of a web scraper. The selector indicates which element to extract the information from. In this example, we are targeting all links, so we are going to type in the
aselector. -
Number results: Define how many matching items you want to extract. The most common ones are “first” and “all”, but you can also extract the last one or even a range of elements.
3. Parse and clean the data
When working with scraped data, you may want to clean or change the extracted information.
Using some scrapers and APIs, you have to do this on your end once you receive the information, but MrScraper provides you with helper parsers to clean the data before it's saved or sent to your desired destination.
Some examples for parsers are: — Remove line breaks or white spaces from the start and end of the text — Replace a piece of text with another one — Remove unwanted text
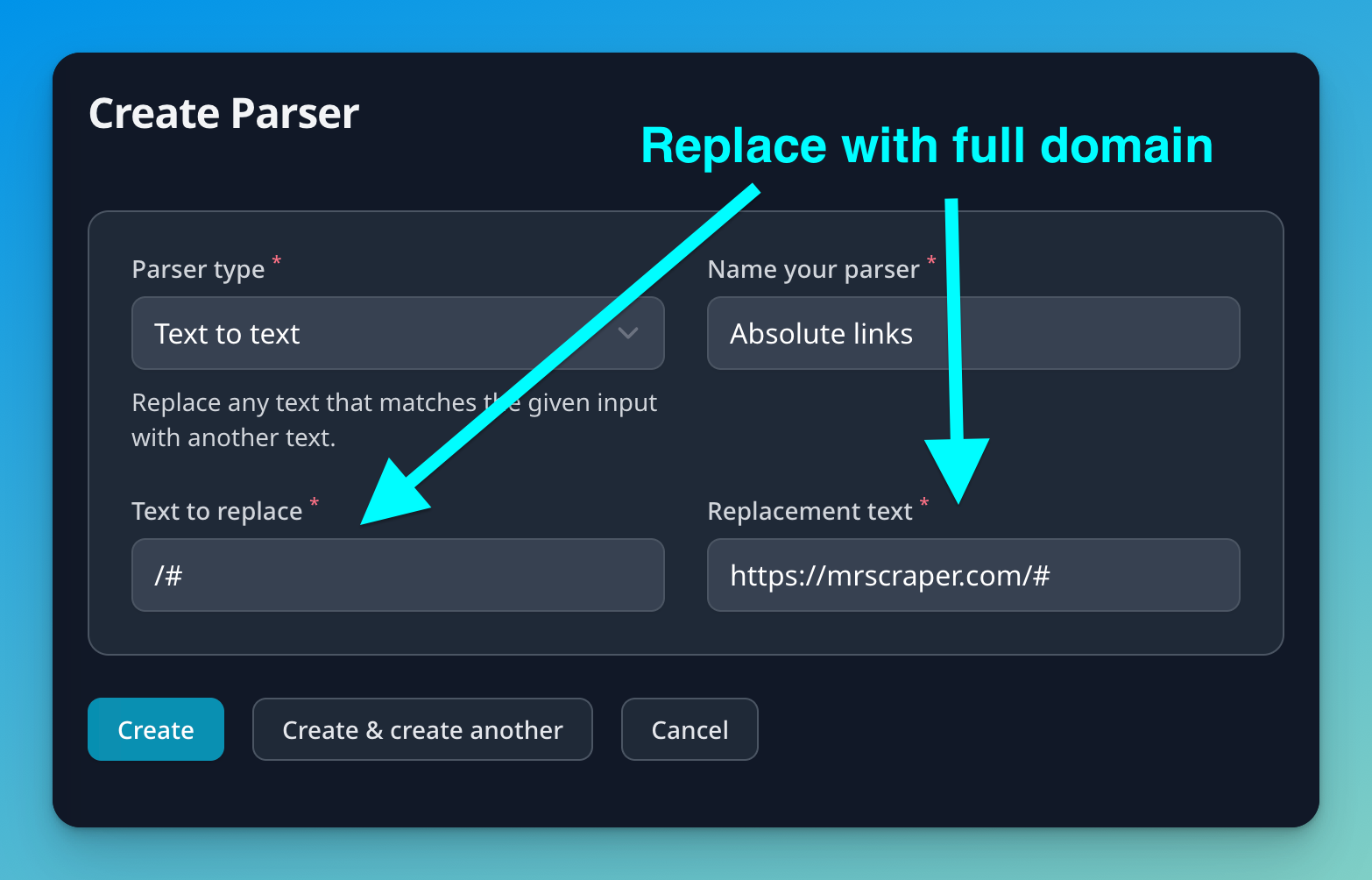
In this example, we are going to use data parsing to convert relative links to absolute ones: /#pricing → https://mrscraper.com/#pricing.
To get started with data parsing, click the “Parsers” menu item from your left sidebar. Then, click on “New parser”.
Next, we have to:
- Select parser type: We will select “text to text” to replace some part of the text for the full domain.
- Name the parser: To make it easier to later add it to extractors.
-
Text to replace: We want to search for the following pattern in text
/#, which means it's a relative URL. -
Replacement text: We are going to replace the previous matches with this text. In our case, we would like to add our domain
https://mrscraper.com/#.
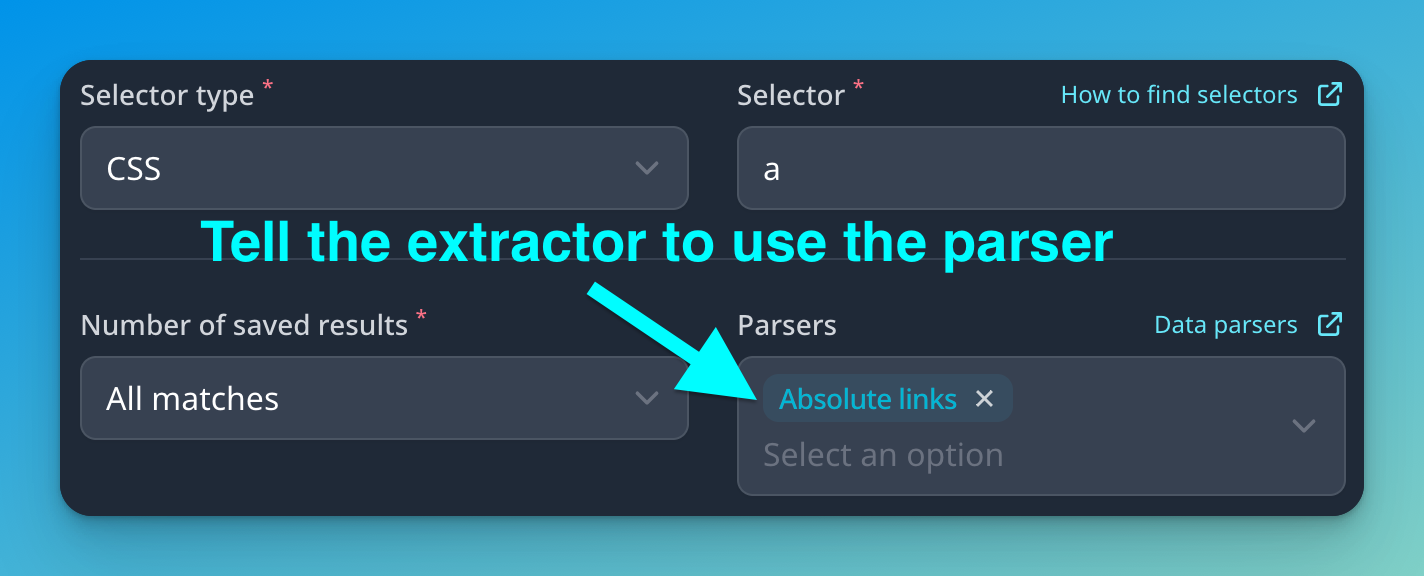
Now that we have the data parser created, we want to add it to our extractor, inside our web scraper.
Navigate back to your scraper and hit “Edit scraper”. Find the extractor for all_links, add the parser and hit save.
4. Check your scraping results
We now have everything set up, and we are ready to push the “Run” button. Once we do this, the scraper will be sent to the queue and start scraping as soon as possible. In a few seconds, we should have our data returned to us.
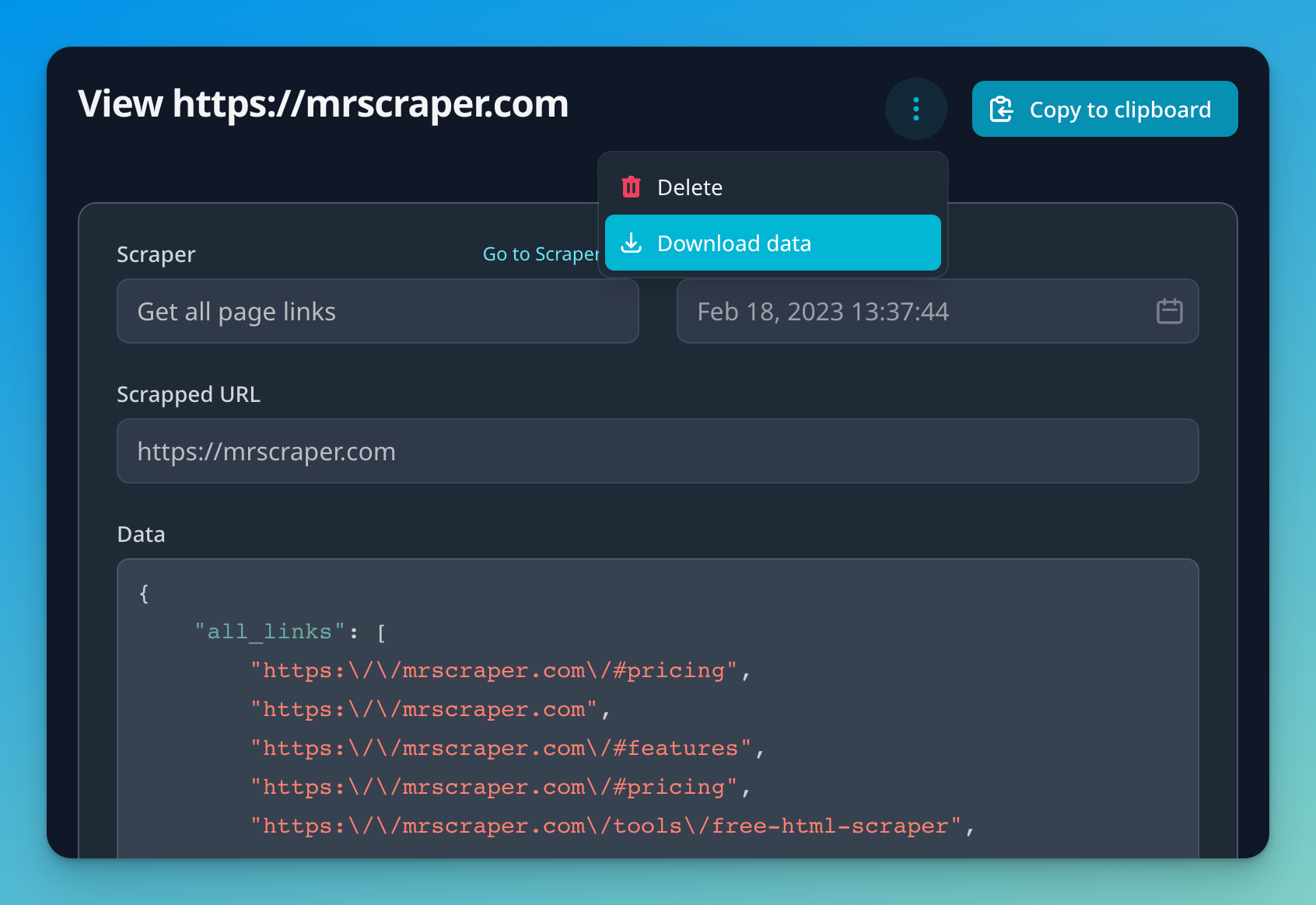
To view your extracted data, go to the “Results” sidebar menu item and find the most recent result.
In this view, we can perform the follow actions:
- Inspect the resulting JSON object
- Copy the data to your clipboard
- Download a JSON file with the extracted data
5. Integrate with any app
Being able to inspect, copy and download the extracted is great in some scenarios. But most of the time, we want to automate and do something with this data as soon as it's available.
MrScraper offers multiple solutions to share the data with you so you can choose the one that better fits your workflow.
- No-code apps: MrScraper has integrations with no-code platforms (such as Zapier) that you can use to listen for new results and send the data to any app you can imagine. For example, add the data to a Google Sheets, send it by email or slack, update a database, etc.
- Webhooks: Webhooks send the scraping results in real time to your desired URLs. Meaning this that you can directly integrate your app with MrScraper.
- API: MrScraper also exposes a public API to do common operations with your scrapers and results.
But going back to our example, we are going to use Zapier to send our extracted data by email.
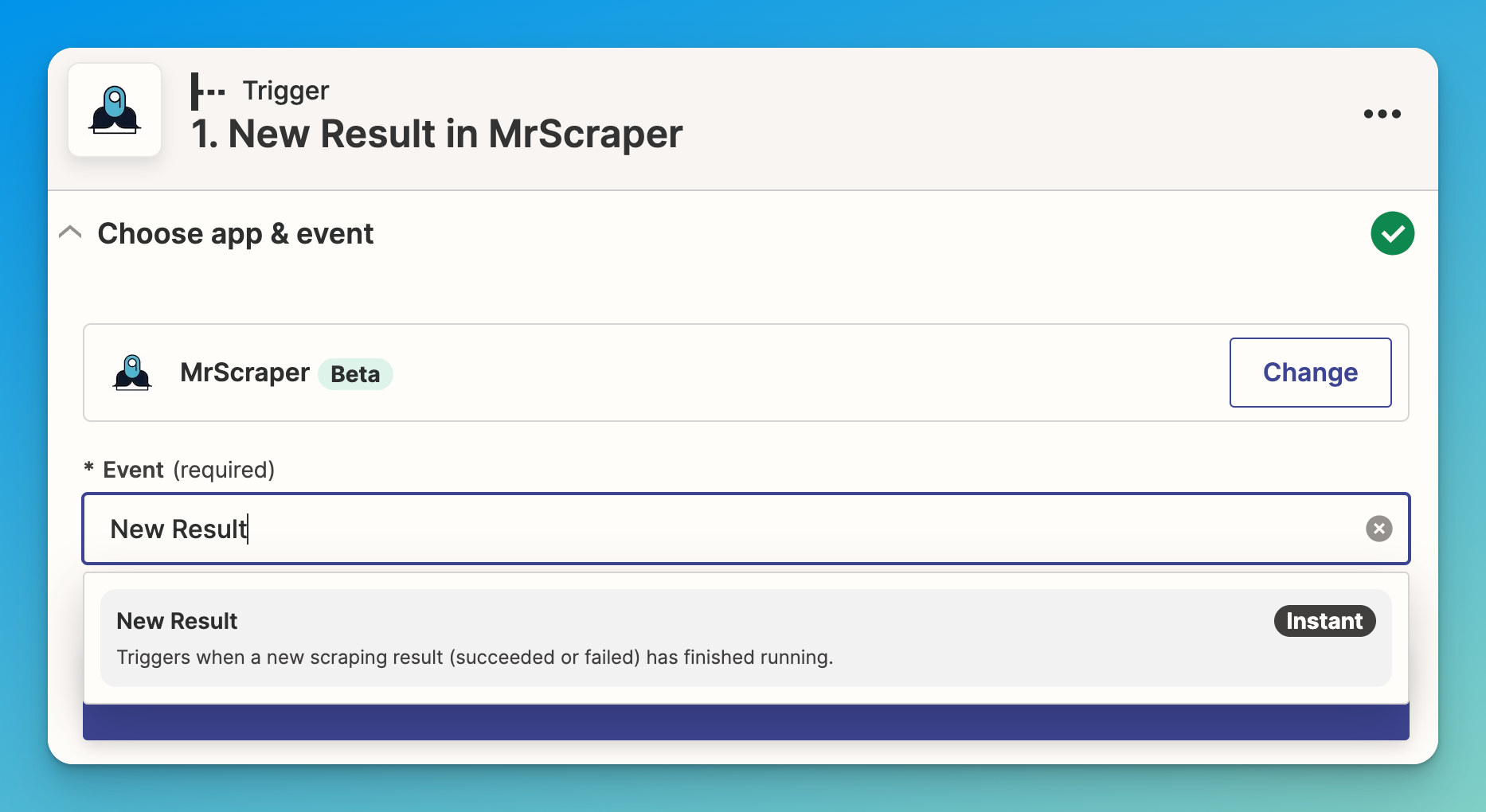
- Login to your Zapier account and create a new Zap.
- The first step, will be to select the MrScraper app and “New Result” as the event we want to listen for. For this step, you will also need a MrScraper API token to get the data from your scrapers. Go to MrScraper and generate a new token with all the available permissions and use it to authenticate your requests from Zapier.
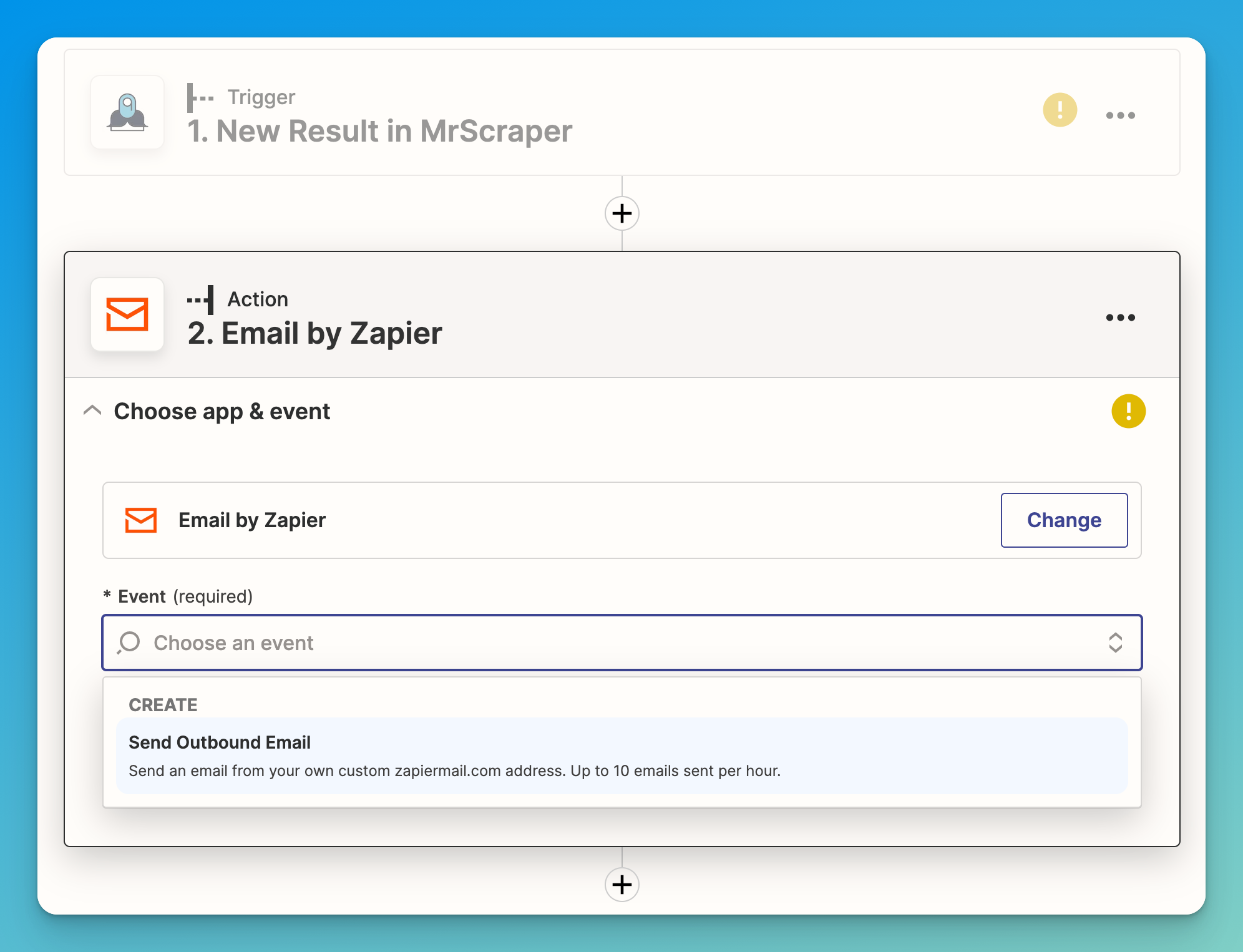
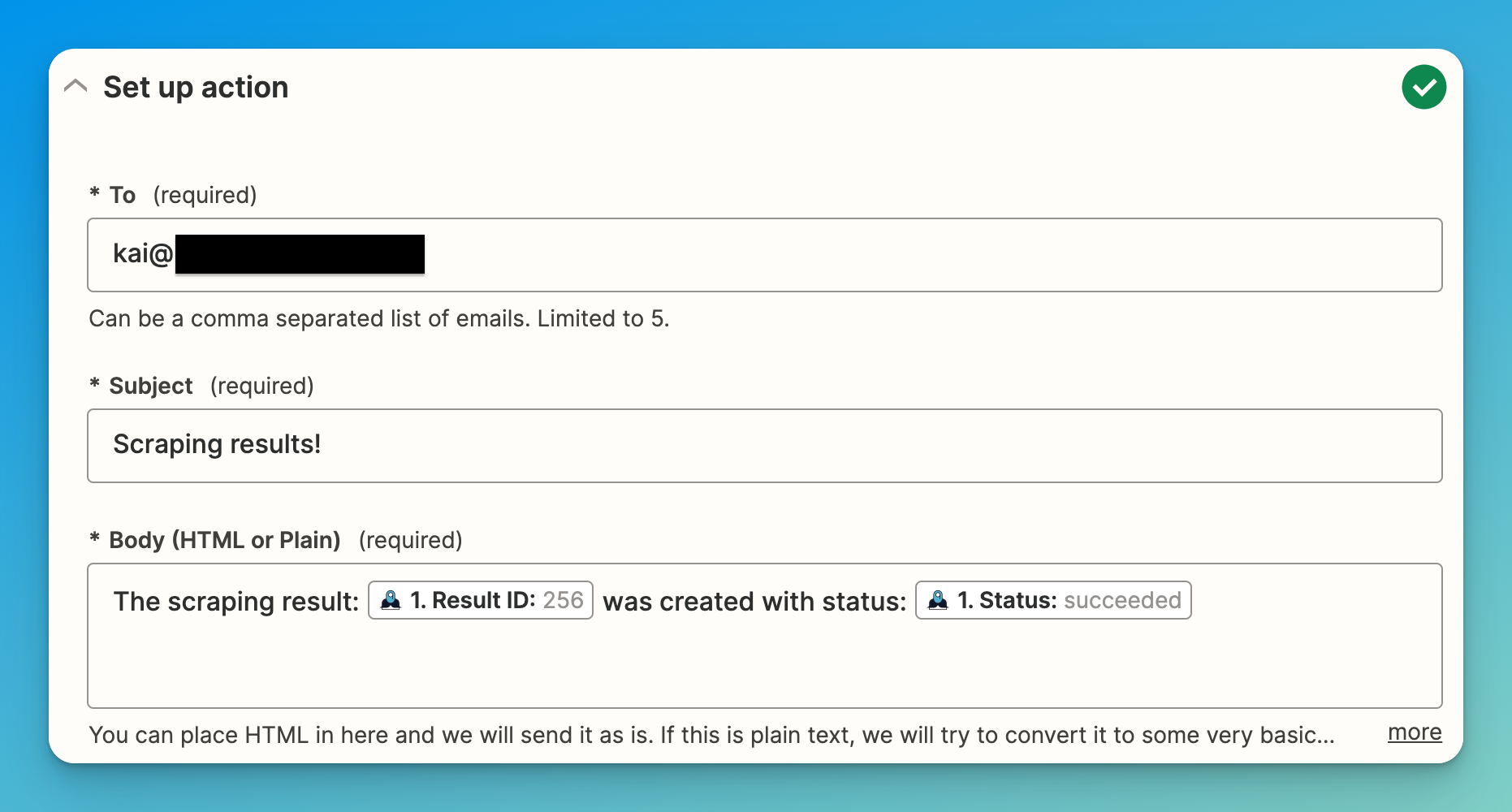
- The second step is to create an action that will run every time the MrScraper event is fired. As we said, we are going to send an email using the “Email by Zapier” action and the “Send outbound email” event.
- Finally, fill the email with the desired information, and you are good to go!
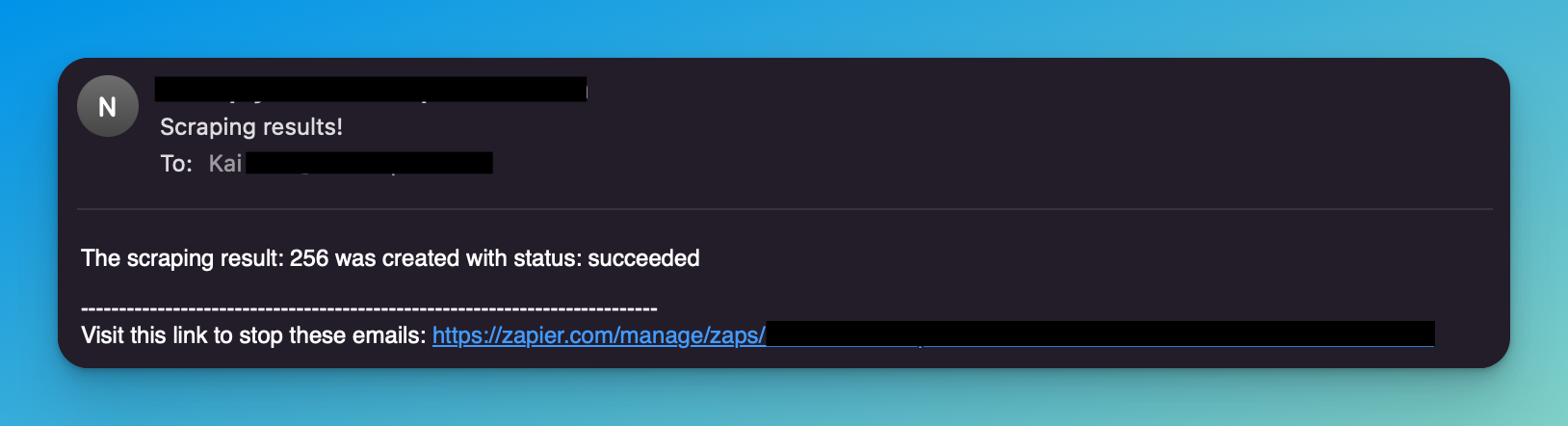
- We publish the Zap and run the scraper. In a few moments, we will receive the email with the data we wanted. It works! ?
Conclusion
MrScraper is an excellent tool that simplifies the complex and technical process of web scraping. With MrScraper, you can extract data from websites easily and quickly, without requiring any programming knowledge or technical background.
The user-friendly interface allows you to create scrapers, define extractors, parse, and clean the data. Plus, you can integrate MrScraper with your favorite tools, making it an all-in-one solution for your data needs.
If you're interested in web scraping, sign up for a free account today and see for yourself how MrScraper can streamline your web scraping process.







