guide Converting cURL Commands to Python for Efficient Web Scraping
 Web scraping is an essential technique for extracting data from websites. Two popular tools for this task are cURL and Python. cURL is a command-line tool used for transferring data with URLs, while Python offers powerful libraries that make web scraping more efficient and user-friendly. This article will explore the basics of cURL, its advantages, and how to convert cURL to Python for efficient web scraping.
Web scraping is an essential technique for extracting data from websites. Two popular tools for this task are cURL and Python. cURL is a command-line tool used for transferring data with URLs, while Python offers powerful libraries that make web scraping more efficient and user-friendly. This article will explore the basics of cURL, its advantages, and how to convert cURL to Python for efficient web scraping.
Basics of cURL and How It Works
cURL, which stands for "Client URL," is a command-line tool that supports various protocols, including HTTP, HTTPS, FTP, and more. It is widely used for testing APIs, downloading files, and performing HTTP requests. A basic cURL command looks like this:
curl https://api.example.com
This command sends a GET request to the specified URL. cURL also supports other HTTP methods like POST, PUT, DELETE, and allows adding headers, data, and authentication.
Example of a POST request with cURL:
curl -X POST https://api.example.com/data -H "Content-Type: application/json" -d '{"key":"value"}'
This command sends a POST request with a JSON payload.
Advantages of Using Python for Web Scraping
While cURL is excellent for quick tests and simple requests, Python offers several advantages for more complex web scraping tasks:
-
Libraries and Frameworks:
Python has powerful libraries like requests, BeautifulSoup, and Scrapy that simplify web scraping. These libraries handle various aspects of web scraping, from making HTTP requests to parsing HTML and handling cookies and sessions.
-
Code Readability and Maintenance:
Python code is often more readable and maintainable than equivalent shell scripts using cURL. Python’s syntax is clean and expressive, making it easier to write and debug web scraping scripts.
-
Automation and Integration:
Python can easily integrate with other tools and libraries, allowing for automation and more complex data processing workflows. For example, you can use Python to scrape data and then directly analyze it using libraries like pandas.
Step-by-Step Guide: Converting cURL to Python
Let's convert some common cURL commands to Python using the requests library.
Simple GET Request
cURL:
curl https://api.example.com/data
Python:
import requests
response = requests.get('https://api.example.com/data')
print(response.text)
GET Request with Headers
cURL:
curl -H "Authorization: Bearer your_token" https://api.example.com/data
Python:
import requests
headers = {
'Authorization': 'Bearer your_token'
}
response = requests.get('https://api.example.com/data', headers=headers)
print(response.text)
POST Request with Data
cURL:
curl -X POST https://api.example.com/data -H "Content-Type: application/json" -d '{"key":"value"}'
Python:
import requests
import json
url = 'https://api.example.com/data'
headers = { 'Content-Type': 'application/json' }
data = { 'key': 'value' }
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.text)
Tips and Best Practices
Error Handling
Always include error handling in your Python scripts to manage unexpected responses or network issues. Use try-except blocks to catch exceptions.
try:
response = requests.get('https://api.example.com/data')
response.raise_for_status() # Raises an HTTPError for bad responses
print(response.text)
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
Respect Website Policies
Respect the robots.txt file of websites and avoid overloading servers with too many requests in a short period. Use time delays between requests if necessary.
User Agents and Headers
Customize your headers to mimic a regular browser and avoid getting blocked.
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get('https://api.example.com/data', headers=headers)
Using Python for Web Scraping
First thing first, specify the website you want to scrape. This can be one of the examples.
Step 1. You will need to import requests, json, BeautifulSoup.
import requests
import json
from bs4 import BeautifulSoup
Step 2. Create a variable for the URL of the website you want to scrape.
url = 'https://mrscraper.com/docs/api/v1'
Step 3. Create a variable for the headers.
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
Step 4. Make the request using requests.
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # Raises an HTTPError for bad responses
print(response.text)
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
Step 5. Create a BeautifulSoup object. It is for parsing HTML and extracting data.
soup = BeautifulSoup(response.text, 'html.parser')
Step 6. Then, you will need to look into the website, find which part of the website you want to scrape, and get the selector. You can get the selector by inspecting the page (Right click on the page -> Inspect).
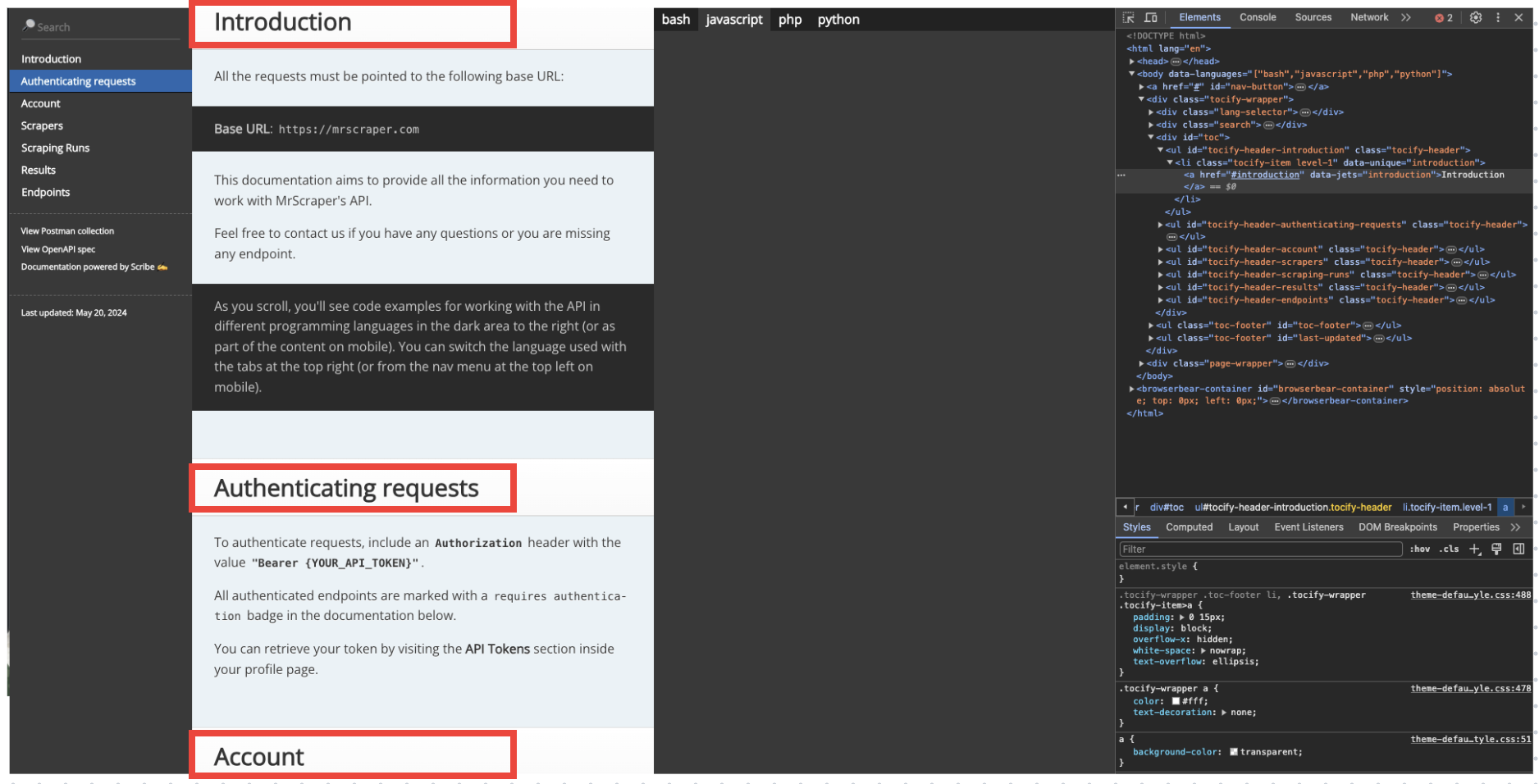
For example, you want to get all the section titles (Introduction, Authenticating requests, Account, …). You can click one of the section titles and find the selector on the right ride or in the tooltip that appears if you hover the section title.
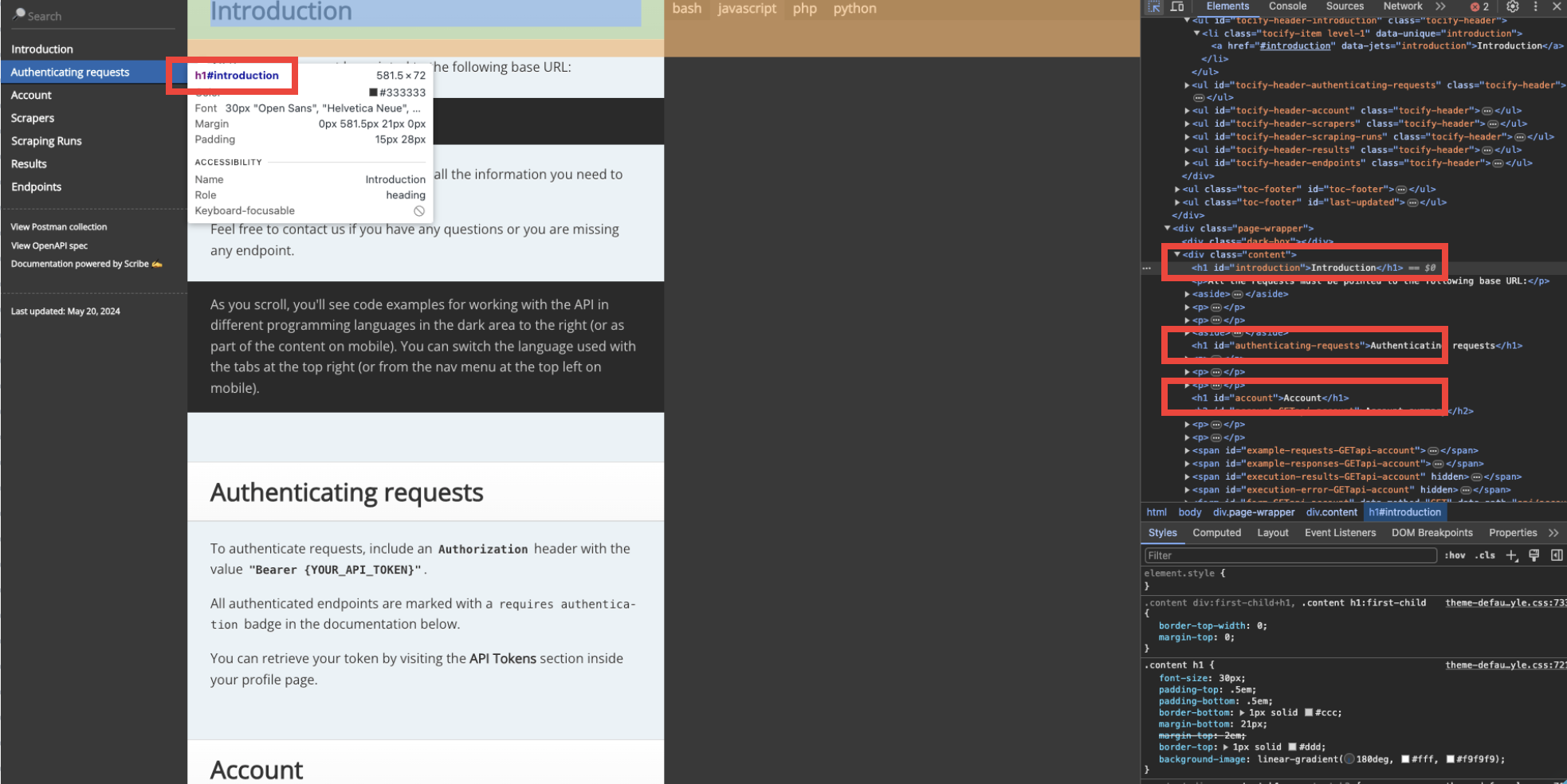
As you can see, the section titles are h1 elements inside a div that has content class.
Step 7. So you can get the div element first
div_element = soup.find('div', class_='content')
Step 8. Get the section titles.
section_titles = div_element.findAll('h1')
for section_title in section_titles:
print(section_title.text)
Here is the complete Python script:
import requests
import json
from bs4 import BeautifulSoup
url = 'https://mrscraper.com/docs/api/v1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # Raises an HTTPError for bad responses
print(response.text)
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
soup = BeautifulSoup(response.text, 'html.parser')
div_element = soup.find('div', class_='content')
section_titles = div_element.findAll('h1')
for section_title in section_titles:
print(section_title.text)
Converting cURL commands to Python can significantly enhance your web scraping capabilities. Python's rich ecosystem of libraries, readability, and ease of integration make it a powerful tool for web scraping tasks. By following the steps and best practices outlined in this article, you can efficiently convert cURL to Python and build robust web scraping scripts. So now you can create your own web scraper from scratch! What do you think about it? It’s quite challenging, isn’t it? Especially if you are not familiar with the libraries and the language. But don’t worry! MrScraper will help you to easily do scraping. You can go here to read the features. Happy scraping!







